KV Fabric: Building a Distributed KV Store Where Consistency Is a Per-Request Choice
{A}Table of Contents
In December 2020, Amazon published a blog post that quietly embarrassed an entire generation of distributed systems design.
Amazon S3 was making its reads strongly consistent - effective immediately.
For fifteen years before that, S3 had offered eventual consistency for overwrite operations - when someone uploaded a new version of an object and immediately read it back, they might still get the old one.
There were many workarounds to overcome this limitation such as retry loops with exponential backoff, cache-invalidation logic, "read-after-write delay" hacks, conditional checks before every critical operation. Entire architectural decisions were made to accommodate S3's consistency model.
Then AWS flipped the switch. Performance and availability didn't suffer, and the infrastructure change was invisible to users. However, with it came an uncomfortable implication: engineering teams had been paying the complexity tax of eventual consistency for operations that never needed it.
But that announcement also raised the question nobody was asking out loud: if strong consistency is now free on S3, should we make everything strongly consistent? And the answer to that question - once you think it through - is definitively no.
A bank balance and a profile picture are not the same. A flight seat availability check and a "last seen 2 minutes ago" timestamp are not the same. One stale read causes a double booking and a lawsuit while the other causes a millisecond discrepancy that no user will ever notice.
A common mistake people make is applying the same consistency level to every operation in a system without asking what each operation actually needs.
Almost every backend who has read DDIA understands the CAP theorem, linearizability, sequential consistency, causal consistency, and eventual consistency. But very few could answer a concrete question: for a specific read path in a real running cluster, what does "eventual" cost me in stale reads per thousand? What does "strong" cost me in milliseconds of latency? What does "read-your-writes" actually buy me over eventual?
I also had these questions and intuitions but not numbers.
So I built kv-fabric.
It is a distributed key-value store where every read explicitly declares the consistency level it needs (via an X-Consistency header). Under the hood it runs a real 3-node Raft cluster powered by Raftly (the production-grade Raft consensus library I built in a previous project).
On top of that sits a real MVCC storage engine, four consistency mode implementations, four runnable failure scenarios each modeled on a real production incident, and a benchmark that produces actual latency and stale-read numbers for every trade-off.
Most distributed systems posts describe consistency models. kv-fabric is a laboratory for measuring them.
This post is the story of what I built, what I broke, and what I learned.
The Problem With Picking One Consistency Level
Before I describe what I built, it is worth being precise about what "consistency" means here, because it can mean different things depending on the context.
In a single-node database, reads always see the latest write. That is free because there is no replication lag: every read and write touches the same data structure. In a distributed system, we write to node A and read from node B. What B knows may lag behind A. The question is: how much, and does it matter for this operation?
The four models kv-fabric implements:
Linearizability (strong consistency)
Strong consistency means every read sees the most recent write, without exceptions. The system behaves as if there is exactly one copy of the data, even though it is replicated across multiple nodes. To make this guarantee, the serving node must confirm it is still the authoritative leader before answering - because a leader that has been partitioned away might be unaware that a new leader was elected in the meantime and newer writes were committed elsewhere.
In Raft terms, the leader sends a heartbeat to a quorum of followers and waits for acknowledgments before serving the read. This confirms two things: the node is still the leader, and the cluster has not elected a replacement since the last heartbeat. The cost is one additional network round-trip per read.
Example: An airline checks whether seat 14C is available before confirming a booking. This read must be strongly consistent. If the check lands on a follower that is 200ms behind, it may return "available" even though another passenger booked the seat moments ago. Two passengers end up with the same seat. With X-Consistency: strong, the read confirms leadership before answering. Therefore, stale data is structurally impossible.
1# Alice books seat 14C
2PUT /v1/keys/flight:UA456:seat:14C {"value": "booked:Alice"}
3→ 200 OK {"version": 1042}
4
5# Bob checks availability - must see Alice's booking
6GET /v1/keys/flight:UA456:seat:14C
7X-Consistency: strong
8→ 200 OK {"value": "booked:Alice", "version": 1042, "is_stale": false}1# Alice books seat 14C
2PUT /v1/keys/flight:UA456:seat:14C {"value": "booked:Alice"}
3→ 200 OK {"version": 1042}
4
5# Bob checks availability - must see Alice's booking
6GET /v1/keys/flight:UA456:seat:14C
7X-Consistency: strong
8→ 200 OK {"value": "booked:Alice", "version": 1042, "is_stale": false}Eventual consistency
Eventual consistency is a loose model that favors availability over freshness. Writes go to the leader, which replicates them to followers asynchronously. Reads can be served from any node (including followers that have not yet received the latest writes). The read may return stale data, but the system guarantees that all replicas will converge to the same state given enough time and no new writes.
There is no upper bound on how stale a read might be. Under normal conditions on a healthy LAN, replication lag is typically or less. During a traffic spike or a slow follower, it can reach or more. Eventual consistency requires zero coordination between nodes before serving a read (no extra network round-trip), which makes it the cheapest option, but it places the entire burden of deciding whether staleness is acceptable squarely on the application.
Example: A product page shows a view count. A user visits and the counter increments. Another user loads the same page 100ms later from a different follower and sees the old count. Nobody is harmed. The count will catch up. This is a perfect use case for eventual consistency - maximum read throughput, zero coordination cost, and a momentary display discrepancy that no user will ever notice or care about.
1# Counter incremented on leader
2PUT /v1/keys/product:22:views {"value": "10001"}
3→ 200 OK {"version": 2051}
4
5# Another user reads from a lagging follower — stale is fine here
6GET /v1/keys/product:22:views
7X-Consistency: eventual
8→ 200 OK {"value": "10000", "version": 2049, "is_stale": true, "lag_ms": 85}1# Counter incremented on leader
2PUT /v1/keys/product:22:views {"value": "10001"}
3→ 200 OK {"version": 2051}
4
5# Another user reads from a lagging follower — stale is fine here
6GET /v1/keys/product:22:views
7X-Consistency: eventual
8→ 200 OK {"value": "10000", "version": 2049, "is_stale": true, "lag_ms": 85}Read-Your-Writes (session consistency)
Read-Your-Writes guarantees that within a client session, a user always sees their own prior writes - even when reading from a follower. Other clients in other sessions may still see older data, but the writing client is never surprised by their own write disappearing on the next read.
The mechanism is a session token. After a successful write, the server encodes the Raft log index of that write into a token and returns it to the client. On the next read, the client sends that token in the request header. The serving node checks whether its applied index has reached the version in the token. If it has, it serves the read locally - no round-trip to the leader required. If it has not, it returns HTTP 503 with a Retry-After header, prompting the client to retry after the follower has had time to catch up (typically 1–10ms on a LAN). The coordination cost is effectively a one-time synchronization per write; once the follower catches up, all subsequent reads in the session are served locally at full follower speed.
Example: A user updates their profile bio and immediately clicks their own profile page to verify the change. Without RYW, the GET might land on a follower that hasn't applied the write yet, and the user sees their old bio - a confusing experience that erodes trust. With the session token, the follower checks whether it has caught up to the write version before responding. If it hasn't, it waits a few milliseconds and retries. The user always sees the change they just made.
1# User updates their bio
2PUT /v1/keys/user:101:bio {"value": "Staff Engineer at Acme"}
3→ 200 OK {"version": 3200, "session_token": "eyJub2RlX2lkIjoibm9kZS0xIiwid3JpdGVfdmVyc2lvbiI6MzIwMH0="}
4
5# User immediately views their profile — sends token to any follower
6GET /v1/keys/user:101:bio
7X-Session-Token: eyJub2RlX2lkIjoibm9kZS0xIiwid3JpdGVfdmVyc2lvbiI6MzIwMH0=
8→ 200 OK {"value": "Staff Engineer at Acme", "version": 3200}
9# Follower confirmed it has applied version 3200 before answering1# User updates their bio
2PUT /v1/keys/user:101:bio {"value": "Staff Engineer at Acme"}
3→ 200 OK {"version": 3200, "session_token": "eyJub2RlX2lkIjoibm9kZS0xIiwid3JpdGVfdmVyc2lvbiI6MzIwMH0="}
4
5# User immediately views their profile — sends token to any follower
6GET /v1/keys/user:101:bio
7X-Session-Token: eyJub2RlX2lkIjoibm9kZS0xIiwid3JpdGVfdmVyc2lvbiI6MzIwMH0=
8→ 200 OK {"value": "Staff Engineer at Acme", "version": 3200}
9# Follower confirmed it has applied version 3200 before answeringMonotonic reads
Monotonic reads guarantee that within a session, time never goes backward. If a client has already seen a value at version , any subsequent read will return a value at version N or higher - the client will never observe a regression to an older state. This prevents the jarring experience of, say, seeing a message appear in a feed and then having it disappear on the next refresh because that read landed on a less up-to-date replica.
The mechanism is a client-side watermark. After each read, the client updates its watermark to max(watermark, result.Version). Each subsequent request includes that watermark as a minimum version constraint. Any serving node that has applied at least that version answers the read locally; if a node is behind the watermark, it returns an error and the client retries. Crucially, the watermark lives entirely in the client — the server is completely stateless with respect to sessions. Any node in the cluster can serve a monotonic read as long as it has caught up to the client's watermark, which means this model scales horizontally without any additional coordination infrastructure.
Example: A user is browsing a support ticket thread. They scroll down and see the latest reply at version 4100. On the next page load, their request lands on a different follower that is at version 4050. Without monotonic reads, the latest reply they just saw vanishes, and the thread looks shorter than it did a second ago. With the watermark X-Min-Version: 4100, the follower refuses to answer until it has caught up, ensuring the user's view of the thread only ever moves forward.
1# First read: user sees the latest reply at version 4100
2GET /v1/keys/ticket:88:replies
3X-Consistency: monotonic
4→ 200 OK {"value": "...", "version": 4100}
5# Client updates watermark: max(0, 4100) = 4100
6
7# Next read: client sends watermark; any node at v4100+ can serve it
8GET /v1/keys/ticket:88:replies
9X-Consistency: monotonic
10X-Min-Version: 4100
11→ 200 OK {"value": "...", "version": 4100}
12# Thread never appears to go backward within this session1# First read: user sees the latest reply at version 4100
2GET /v1/keys/ticket:88:replies
3X-Consistency: monotonic
4→ 200 OK {"value": "...", "version": 4100}
5# Client updates watermark: max(0, 4100) = 4100
6
7# Next read: client sends watermark; any node at v4100+ can serve it
8GET /v1/keys/ticket:88:replies
9X-Consistency: monotonic
10X-Min-Version: 4100
11→ 200 OK {"value": "...", "version": 4100}
12# Thread never appears to go backward within this sessionEach of these costs something different. Each defends against a different class of failure. Understanding which one each read path in the system needs is not a performance optimization, but a correctness decision.
What Is kv-fabric?
kv-fabric is a distributed key-value store in Go, built to be a working system rather than a thought experiment.
The Raft consensus is powered by Raftly, a production-grade Raft library I built as a separate project. Raftly handles the hard parts of consensus: leader election, log replication, pre-vote, fast log backtracking, and WAL-backed durability. kv-fabric plugs into it through a thin adapter interface (raftly_adapter.go), which keeps the consensus machinery completely decoupled from the storage and consistency layers above it.
The scenarios and benchmark use an in-process cluster where all three nodes run inside a single Go process and communicate over channels instead of TCP. It is worth being clear about what "in-process" means here: every leader election, log replication, and quorum commit runs the real Raft algorithm. The only thing absent is network latency. The behavior is identical to a networked cluster: only the RTT is missing.
The four layers
The project is organized into four horizontal layers. Each layer has a single responsibility and knows nothing about the layers above it:
Store (store/)
This is the MVCC storage engine which stores versioned values, serves reads, and runs garbage collection. It has no knowledge of Raft, networking, or consistency modes.
Replication (replication/)
This is the bridge between Raft and storage. It reads committed log entries from Raftly and applies them to the MVCC engine in order. It also tracks follower replication lag and manages on-disk snapshots for log compaction.
Consistency (consistency/)
This is the read router. It inspects the X-Consistency header on each request and dispatches the read to the correct reader implementation. It never touches Raft internals directly.
Server (server/)
This is the HTTP REST and gRPC API layer. It parses request headers, redirects writes from non-leader nodes to the leader, and exposes Prometheus metrics.
Because lower layers never import upper ones, each layer can be tested in complete isolation. The MVCC engine has no idea a Raft cluster exists. The replication layer has no idea an HTTP server exists. This makes unit tests fast and focused: a bug in the storage engine shows up in storage tests, not buried inside an integration test that requires a running cluster.
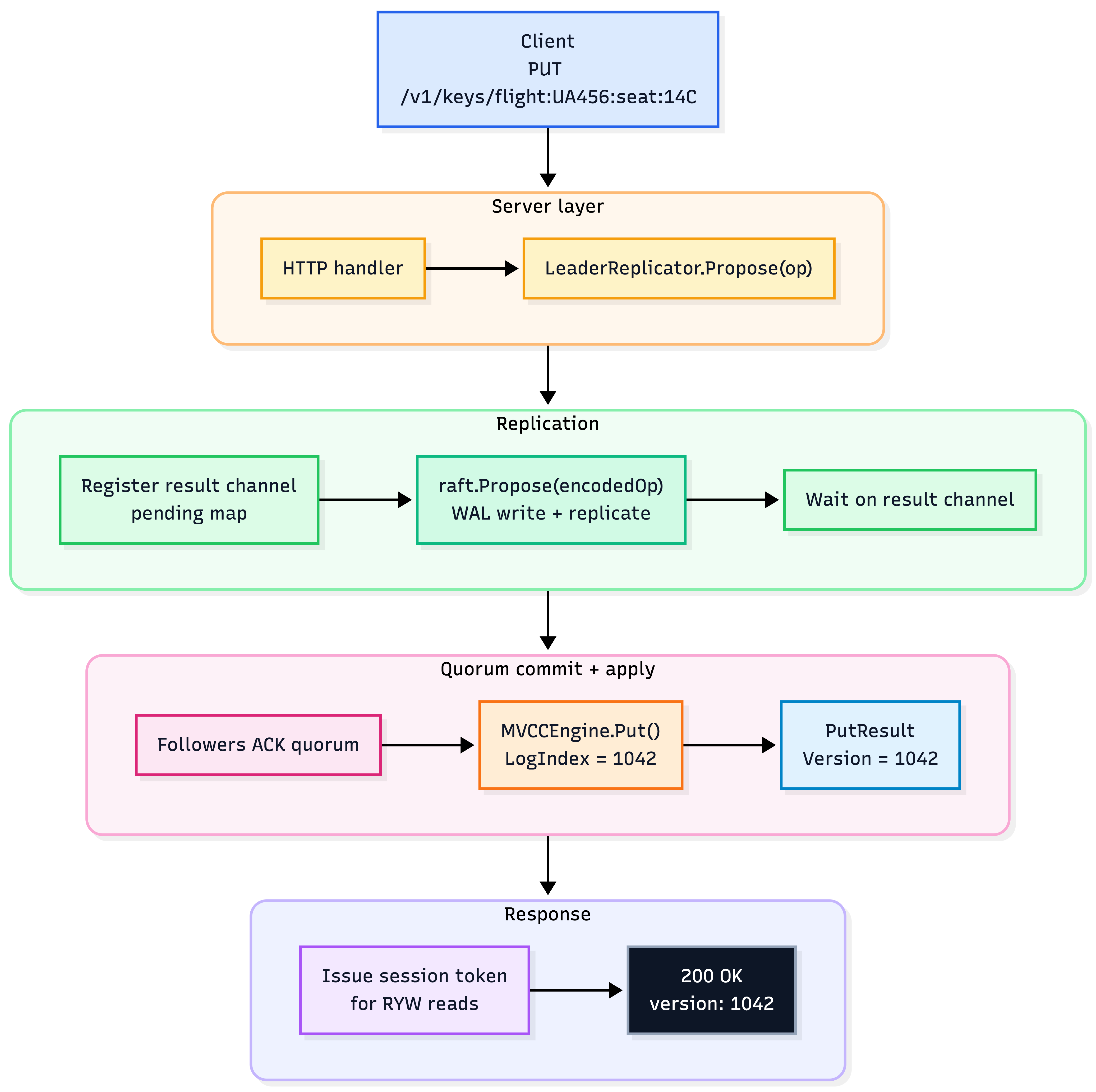
How a write travels through every layer
To make this concrete, here is a single PUT request traced from the client all the way down to the storage engine and back:
 Zoom
Zoom
Every step has a strict ordering. None of these can be re-sequenced without breaking either durability or the commit guarantee. The version number returned to the client is the Raft log index at which the entry was committed. That same index becomes the MVCC version number on every node in the cluster, which is the design decision we will explore in the next section.
The MVCC Engine: Raft Log Index as Version Number
The most interesting engineering decision in kv-fabric lives in the storage layer. Every MVCC version number is a Raft log index.
When the replication layer applies log entry at index , it calls engine.Put(key, value, PutOptions{LogIndex: 5000}). The engine stores that write with version . On the leader. On every follower. On every node in the cluster, for every key, the write at log index is version . Always. Without any coordination.
This may look trivial but the implications of it are significant.
Most MVCC systems maintain a version counter separate from the replication log. They might use a monotonically increasing sequence in a central service, or a hybrid logical clock, or a distributed timestamp. All of these require coordination or make assumptions about clock synchronization. All of them add moving parts that can fail or drift.
In kv-fabric, the Raft consensus layer is already establishing a total order of operations and assigning a unique, monotonically increasing index to each one. That index is the perfect version number: globally unique, monotonically increasing, and identical on every node that has applied the same log entry. Same inputs, same order, same version — the state machine property works in our favor.
The data model looks like below:
1type VersionChain struct {
2 mu sync.RWMutex
3 versions []Version // oldest-first: versions[0] = oldest, versions[len-1] = current
4 pinned uint64 // GC must not collect anything >= pinned while a txn is active
5}
6
7// Example:
8//
9// e.data["flight:UA456:seat:14C"] → VersionChain{
10// versions: [
11// {Num: 1001, Value: "available"}, ← baseline write
12// {Num: 1042, Value: "booked:Alice"}, ← Alice's booking
13// {Num: 1099, Value: "booked:Bob"}, ← current value (Bob won)
14// ]
15// }1type VersionChain struct {
2 mu sync.RWMutex
3 versions []Version // oldest-first: versions[0] = oldest, versions[len-1] = current
4 pinned uint64 // GC must not collect anything >= pinned while a txn is active
5}
6
7// Example:
8//
9// e.data["flight:UA456:seat:14C"] → VersionChain{
10// versions: [
11// {Num: 1001, Value: "available"}, ← baseline write
12// {Num: 1042, Value: "booked:Alice"}, ← Alice's booking
13// {Num: 1099, Value: "booked:Bob"}, ← current value (Bob won)
14// ]
15// }Each entry in the chain is a Version struct:
1type Version struct {
2 Num uint64 // Raft log index: the global write-order position; this IS the version number
3 Value []byte // raw bytes of the stored value; nil for tombstones
4 Timestamp time.Time // wall-clock time when this version was applied (informational only)
5 TxnID uint64 // transaction that created this version; 0 for non-transactional writes
6 Deleted bool // true = this is a tombstone — the key was logically deleted at this version
7}1type Version struct {
2 Num uint64 // Raft log index: the global write-order position; this IS the version number
3 Value []byte // raw bytes of the stored value; nil for tombstones
4 Timestamp time.Time // wall-clock time when this version was applied (informational only)
5 TxnID uint64 // transaction that created this version; 0 for non-transactional writes
6 Deleted bool // true = this is a tombstone — the key was logically deleted at this version
7}Numis the most important field. It is the Raft log index of the committed entry that produced this write: globally ordered, unique, and identical on every node in the cluster.Valuecarries the raw payload.Deletedis a tombstone flag: rather than physically removing a key, a delete operation appends a newVersionwithDeleted: true. This preserves history and lets GC handle cleanup uniformly, instead of requiring special-case deletion logic scattered through the codebase.TxnIDlinks a version to a multi-key transaction, so the engine knows to apply a batch of writes atomically when the transaction commits: all operations in the batch get the sameNum, and they either all appear or none do.
When a client writes, a new Version is appended to the chain. Old versions are never overwritten in place. This immutability is what enables three things simultaneously:
- Consistent snapshot reads: A transaction that pinned version always sees
"booked:Alice", even as version is written concurrently. Because the chain is append-only, nothing at or below index 1042 ever changes. The pinned transaction's view of the world is frozen at the moment it started. - Point-in-time reads:
GetAtVersion(key, 1042)walks the chain backward and returns the latestVersionwhoseNum <= 1042. This answers the question "what was the value of this key at Raft log index ?". It is useful for snapshot isolation and audit reads. - Monotonic reads:
Get(key, {MinVersion: 1042})walks the chain and returns the latestVersionwhoseNum >= 1042. This ensures the result is at least as recent as the client's watermark, so time never goes backward within a session.
The Put implementation enforces a strict locking discipline:
1func (e *MVCCEngine) Put(key string, value []byte, opts PutOptions) (*PutResult, error) {
2 // Step 1: get or create the version chain - needs engine write lock
3 e.mu.Lock()
4 chain := e.getOrCreateChain(key)
5 e.mu.Unlock() // Engine lock released. From here we only touch this one chain.
6
7 // Step 2: write to the chain - needs only chain write lock
8 chain.mu.Lock()
9 defer chain.mu.Unlock()
10
11 if opts.IfVersion != 0 {
12 current := chain.latestLocked()
13 currentNum := uint64(0)
14 if current != nil {
15 currentNum = current.Num
16 }
17 if currentNum != opts.IfVersion {
18 return nil, fmt.Errorf("CAS failed for %q: expected v%d, found v%d",
19 key, opts.IfVersion, currentNum)
20 }
21 }
22
23 version := opts.LogIndex // production path: Raft log index = version number
24 if version == 0 {
25 version = versionSeq.Add(1) // unit-test fallback only
26 }
27
28 chain.versions = append(chain.versions, Version{
29 Num: version,
30 Value: makeCopy(value), // defensive copy: caller may reuse their slice
31 Timestamp: time.Now(),
32 })
33 return &PutResult{Version: version, AppliedAt: time.Now()}, nil
34}1func (e *MVCCEngine) Put(key string, value []byte, opts PutOptions) (*PutResult, error) {
2 // Step 1: get or create the version chain - needs engine write lock
3 e.mu.Lock()
4 chain := e.getOrCreateChain(key)
5 e.mu.Unlock() // Engine lock released. From here we only touch this one chain.
6
7 // Step 2: write to the chain - needs only chain write lock
8 chain.mu.Lock()
9 defer chain.mu.Unlock()
10
11 if opts.IfVersion != 0 {
12 current := chain.latestLocked()
13 currentNum := uint64(0)
14 if current != nil {
15 currentNum = current.Num
16 }
17 if currentNum != opts.IfVersion {
18 return nil, fmt.Errorf("CAS failed for %q: expected v%d, found v%d",
19 key, opts.IfVersion, currentNum)
20 }
21 }
22
23 version := opts.LogIndex // production path: Raft log index = version number
24 if version == 0 {
25 version = versionSeq.Add(1) // unit-test fallback only
26 }
27
28 chain.versions = append(chain.versions, Version{
29 Num: version,
30 Value: makeCopy(value), // defensive copy: caller may reuse their slice
31 Timestamp: time.Now(),
32 })
33 return &PutResult{Version: version, AppliedAt: time.Now()}, nil
34}The locking discipline here is deliberate. There are two separate locks rather than one global lock, because a single lock protecting the entire engine would mean every write to key:A blocks every concurrent read from key:B — unnecessary serialization across unrelated keys.
Instead, e.mu guards only the top-level map lookup and is released as soon as the target chain is found. From that point on, only chain.mu is held, so two operations on different keys proceed in parallel without ever contending on the same lock.
The ordering rule: always acquire e.mu first, then chain.mu, never the reverse is what prevents deadlock. A deadlock by lock-ordering inversion happens when goroutine A holds lock 1 and waits for lock 2, while goroutine B holds lock 2 and waits for lock 1. Neither can proceed. By enforcing a single consistent acquisition order across every method in the engine, this situation can never arise: no goroutine ever holds chain.mu while trying to acquire e.mu.
Garbage Collection Without Blocking Writers
The MVCC model keeps every write in memory until GC can safely reclaim it. GC cannot arbitrarily delete versions — that would break any concurrent transaction that has pinned an older snapshot.
kv-fabric implements a two-factor GC horizon:
1func (e *MVCCEngine) computeEffectiveHorizon() (horizon, oldestPin uint64, blocked bool) {
2 e.mu.RLock()
3 horizon = e.gcHorizon // min(follower matchIndexes): set by replication layer
4 chains := /* snapshot chain pointers */
5 e.mu.RUnlock()
6
7 for _, chain := range chains {
8 chain.mu.RLock()
9 pinned := chain.pinned
10 chain.mu.RUnlock()
11
12 if pinned != 0 && pinned < horizon {
13 horizon = pinned // oldest active transaction wins
14 oldestPin = pinned
15 blocked = true
16 }
17 }
18 return
19}1func (e *MVCCEngine) computeEffectiveHorizon() (horizon, oldestPin uint64, blocked bool) {
2 e.mu.RLock()
3 horizon = e.gcHorizon // min(follower matchIndexes): set by replication layer
4 chains := /* snapshot chain pointers */
5 e.mu.RUnlock()
6
7 for _, chain := range chains {
8 chain.mu.RLock()
9 pinned := chain.pinned
10 chain.mu.RUnlock()
11
12 if pinned != 0 && pinned < horizon {
13 horizon = pinned // oldest active transaction wins
14 oldestPin = pinned
15 blocked = true
16 }
17 }
18 return
19}The replication horizon (gcHorizon) answers the question: how far back does any node in the cluster still need to look? It is computed as the minimum matchIndex across all followers: the highest Raft log index that every node has confirmed applying. Versions at or below that index are safe to collect because no follower can be asked to replay entries from before that point. A lagging follower that has only reached index cannot request entries that GC has already reclaimed, so GC must not run ahead of the slowest follower in the cluster, not the fastest. The replication layer updates gcHorizon continuously as each follower advances.
The transaction pin is a floor that an active read transaction places on GC. When an analytics query starts, it records the current version of each key it reads by calling engine.PinVersion(key, version). That pin tells GC: "someone is reading the world as it looked at version - do not collect anything at or above N while I am still running." As long as the transaction is alive, the effective GC horizon is capped at the pin, even if the replication horizon has moved far ahead. The kv_fabric_mvcc_gc_blocked=1 Prometheus gauge is set whenever an active transaction pin is the limiting factor; a signal that a long-running transaction, not follower lag, is what is holding back memory reclamation.
The GC loop itself is designed to not block writers:
1func (e *MVCCEngine) runGC() {
2 horizon, _, _ := e.computeEffectiveHorizon()
3
4 // Snapshot chain pointers under read lock, then release immediately.
5 // The engine is NOT held during collection — writes proceed unblocked.
6 e.mu.RLock()
7 chains := /* snapshot */
8 e.mu.RUnlock()
9
10 for _, chain := range chains {
11 chain.mu.Lock()
12 chain.collectGarbage(horizon) // only chain lock — sub-microsecond per key
13 chain.mu.Unlock()
14 }
15}1func (e *MVCCEngine) runGC() {
2 horizon, _, _ := e.computeEffectiveHorizon()
3
4 // Snapshot chain pointers under read lock, then release immediately.
5 // The engine is NOT held during collection — writes proceed unblocked.
6 e.mu.RLock()
7 chains := /* snapshot */
8 e.mu.RUnlock()
9
10 for _, chain := range chains {
11 chain.mu.Lock()
12 chain.collectGarbage(horizon) // only chain lock — sub-microsecond per key
13 chain.mu.Unlock()
14 }
15}The rule for what gets collected:
1func (c *VersionChain) collectGarbage(horizon uint64) (collected, bytesFreed int64) {
2 // Always keep:
3 // - The latest version (versions[len-1]): it is the current value of the key
4 // - All versions with Num >= horizon: may be needed for snapshot reads
5 // Collect:
6 // - All non-latest versions with Num < horizon
7 ...
8}1func (c *VersionChain) collectGarbage(horizon uint64) (collected, bytesFreed int64) {
2 // Always keep:
3 // - The latest version (versions[len-1]): it is the current value of the key
4 // - All versions with Num >= horizon: may be needed for snapshot reads
5 // Collect:
6 // - All non-latest versions with Num < horizon
7 ...
8}The always-keep-latest rule matters. Without it, a key that has only one version below the horizon would be deleted entirely - making the key disappear from the engine.
The Consistency Layer: Four Readers, One Interface
Every read in kv-fabric goes through Router.Get(). The router inspects the X-Consistency header on the incoming request and forwards the call to one of its four reader implementations - one per consistency mode. That is all it does. There is no consistency logic inside the router itself; every decision about how to serve the read lives entirely inside the reader it hands off to.
The contract that all four readers share is a single interface:
type Reader interface {
Get(ctx context.Context, key string, opts store.GetOptions) (*store.GetResult, error)
}type Reader interface {
Get(ctx context.Context, key string, opts store.GetOptions) (*store.GetResult, error)
}This interface is the key design decision. Because every consistency mode implements the same Get signature, the router does not need to know anything about how each mode works - it holds four Reader values and calls .Get() on whichever one matches the request.
Each implementation can be written, tested, and reasoned about in complete isolation. A unit test for StrongReader does not need a running Raft cluster; it only needs a mock that satisfies the RaftNode interface. The same applies to EventualReader, RYWReader, and MonotonicReader.
Adding a new consistency mode means writing one new struct that implements Reader and registering it with the router — nothing else in the codebase needs to change.
Strong: The "ReadIndex" Protocol
Linearizable reads require three sequential steps:
1func (r *StrongReader) Get(ctx context.Context, key string, opts store.GetOptions) (*store.GetResult, error) {
2 // Step 1: Snapshot the read fence.
3 // readIndex is the minimum applied index the result must reflect.
4 readIndex := r.raft.CommitIndex()
5
6 // Step 2: Confirm we are still the leader.
7 // Without this, a partitioned leader could serve reads that miss writes
8 // committed by the new true leader.
9 if err := r.raft.ConfirmLeadership(ctx); err != nil {
10 return nil, fmt.Errorf("strong read: leadership confirmation failed: %w", err)
11 }
12
13 // Step 3: Wait for the apply loop to catch up to readIndex.
14 // The commit -> apply path is asynchronous. A committed entry may not yet
15 // be in the engine when CommitIndex() was called.
16 if err := r.waitForApplied(ctx, readIndex); err != nil {
17 return nil, fmt.Errorf("strong read: timed out waiting for applied %d: %w", readIndex, err)
18 }
19
20 // Step 4: Read locally. Confirmed leader, caught up to readIndex.
21 // This read is linearizable.
22 return r.engine.Get(key, opts)
23}1func (r *StrongReader) Get(ctx context.Context, key string, opts store.GetOptions) (*store.GetResult, error) {
2 // Step 1: Snapshot the read fence.
3 // readIndex is the minimum applied index the result must reflect.
4 readIndex := r.raft.CommitIndex()
5
6 // Step 2: Confirm we are still the leader.
7 // Without this, a partitioned leader could serve reads that miss writes
8 // committed by the new true leader.
9 if err := r.raft.ConfirmLeadership(ctx); err != nil {
10 return nil, fmt.Errorf("strong read: leadership confirmation failed: %w", err)
11 }
12
13 // Step 3: Wait for the apply loop to catch up to readIndex.
14 // The commit -> apply path is asynchronous. A committed entry may not yet
15 // be in the engine when CommitIndex() was called.
16 if err := r.waitForApplied(ctx, readIndex); err != nil {
17 return nil, fmt.Errorf("strong read: timed out waiting for applied %d: %w", readIndex, err)
18 }
19
20 // Step 4: Read locally. Confirmed leader, caught up to readIndex.
21 // This read is linearizable.
22 return r.engine.Get(key, opts)
23}All three steps are necessary. Removing any one of them breaks the guarantee:
- Without Step 2 (
ConfirmLeadership): a leader that has been partitioned away can serve reads that miss writes committed by the new true leader. - Without Step 3 (
waitForApplied): even the confirmed leader has a small window between a commit being acknowledged by a quorum and being applied to the local engine. A read in that window is technically stale.
waitForApplied uses exponential backoff starting at . Under normal load, the fast path fires immediately - the apply loop runs within microseconds of commit. The backoff only matters under sustained write pressure.
Read-Your-Writes: The Session Token
The phantom read problem
Before explaining how RYW works, it is worth being clear about the problem it defends against.
In a system with asynchronous replication, a client can write a value to the leader and receive a 200 OK - the write is committed and durable. The client then immediately reads the same key, but the request lands on a follower that has not yet applied the replication update. The follower returns the old value, or nothing at all. From the client's perspective, the write they just confirmed has vanished. This is a phantom read: a successfully committed write that is invisible to the very client who made it.
This is not a hypothetical. On any system where reads are distributed across followers for load balancing, the gap between a write committing on the leader and that write appearing on a follower is real — even on a healthy LAN, it is typically 1–10ms. Any read that arrives in that window will miss the write.
The impact depends on the context. A user who updates their profile bio and refreshes the page to see the old text will be confused and hit refresh again — frustrating but recoverable. A payment service that debits an account, then immediately reads it back to verify the balance before proceeding, and sees the pre-debit amount, may apply the charge twice — not recoverable. In both cases the root cause is the same: no guarantee that a client's own writes are visible to their own subsequent reads.
RYW eliminates phantom reads within a session. After a write, any subsequent read from the same client is guaranteed to be served from a node that has applied at least that write — regardless of which follower the read lands on.
After a successful write, the server issues a session token:
1type SessionToken struct {
2 NodeID string `json:"node_id"`
3 WriteVersion uint64 `json:"write_version"` // Raft log index of the write
4 IssuedAt time.Time `json:"issued_at"`
5}
6
7func IssueToken(nodeID string, writeVersion uint64) (string, error) {
8 t := SessionToken{NodeID: nodeID, WriteVersion: writeVersion, IssuedAt: time.Now()}
9 data, _ := json.Marshal(t)
10 return base64.URLEncoding.EncodeToString(data), nil // URL-safe, readable with any tool
11}1type SessionToken struct {
2 NodeID string `json:"node_id"`
3 WriteVersion uint64 `json:"write_version"` // Raft log index of the write
4 IssuedAt time.Time `json:"issued_at"`
5}
6
7func IssueToken(nodeID string, writeVersion uint64) (string, error) {
8 t := SessionToken{NodeID: nodeID, WriteVersion: writeVersion, IssuedAt: time.Now()}
9 data, _ := json.Marshal(t)
10 return base64.URLEncoding.EncodeToString(data), nil // URL-safe, readable with any tool
11}The client sends this on subsequent GETs via X-Session-Token. The serving node - any node, not just the leader - decodes it and checks one condition:
1appliedIndex := r.raft.AppliedIndex()
2if appliedIndex < token.WriteVersion {
3 // Node hasn't applied the version the client wrote yet.
4 // Return 503 — the HTTP handler adds Retry-After so the client retries shortly.
5 return nil, &ErrNotCaughtUp{
6 RequiredVersion: token.WriteVersion,
7 CurrentVersion: appliedIndex,
8 }
9}
10// Caught up. Serve from local engine - no leader required.
11return r.engine.Get(key, opts)1appliedIndex := r.raft.AppliedIndex()
2if appliedIndex < token.WriteVersion {
3 // Node hasn't applied the version the client wrote yet.
4 // Return 503 — the HTTP handler adds Retry-After so the client retries shortly.
5 return nil, &ErrNotCaughtUp{
6 RequiredVersion: token.WriteVersion,
7 CurrentVersion: appliedIndex,
8 }
9}
10// Caught up. Serve from local engine - no leader required.
11return r.engine.Get(key, opts)On the first retry — after the replication lag typical on a LAN cluster - the follower will have applied the write and serve the read locally. The cost compared to strong reads: one additional request on the first read after a write (the retry), zero cost on all subsequent reads in the same session once the follower catches up.
Why not redirect to the leader on ErrNotCaughtUp? Because that defeats the purpose. The whole point of RYW is to spread read load across followers. Replication lag is typically . A client retry with a sleep will almost always hit the fast path on the second try.
Monotonic Reads: Client-Side Watermarks
After each read, the client tracks watermark = max(watermark, result.Version). On the next request, they send X-Min-Version: <watermark>.
The serving node:
1if opts.MinVersion > 0 && r.raft.AppliedIndex() < opts.MinVersion {
2 return nil, &ErrNotCaughtUp{
3 Mode: "monotonic",
4 RequiredVersion: opts.MinVersion,
5 CurrentVersion: appliedIndex,
6 }
7}
8return r.engine.Get(key, opts) // node is caught up — serve locally1if opts.MinVersion > 0 && r.raft.AppliedIndex() < opts.MinVersion {
2 return nil, &ErrNotCaughtUp{
3 Mode: "monotonic",
4 RequiredVersion: opts.MinVersion,
5 CurrentVersion: appliedIndex,
6 }
7}
8return r.engine.Get(key, opts) // node is caught up — serve locallyThe key property: the watermark lives in the client, not the server. The server is completely stateless with respect to sessions. Any node in the cluster can serve a monotonic read as long as it has caught up to the client's watermark. No server-side session state. No coordination between nodes. Monotonic reads scale horizontally with the cluster size.
When to use monotonic reads vs. strong: use strong when we need to see other clients' latest writes immediately. Use monotonic when we only need your own view of the world to be consistent (browsing a feed: you should not see yesterday's post after seeing today's, but seeing a post from 100ms ago vs. right now does not matter).
The Four Failure Scenarios
Every scenario in kv-fabric reproduces a real production incident. Each one starts a real 3-node Raft cluster, injects a real failure using the NetworkProxy, and prints observable evidence. Run them in order and each one teaches a different lesson about what goes wrong when consistency assumptions are violated.
Scenario 1: The Phantom Write (make scenario-phantom)
The real incident: During MySQL leader-follower failovers at multiple companies, some writes had been acknowledged to clients but had not yet replicated to any follower when the leader crashed. The new leader which was elected from the follower pool had no record of those writes. They were permanently gone, while the clients that made them were holding a 200 OK.
The failure mechanism: The culprit is a common replication strategy called semi-synchronous replication, and specifically its timeout fallback.
Standard asynchronous replication means the leader writes locally and immediately returns success. The followers catch up later. This is fast but risky: if the leader crashes before a follower receives the write, the data is lost.
Semi-synchronous replication was designed to improve this: the leader waits for at least one follower to confirm it has received the write before returning success. Under normal conditions this means the write is on two nodes: the leader and at least one follower before the client is told it succeeded.
The trap is the fallback clause. If no follower responds within the timeout, the leader does not wait forever, it falls back to async and returns success anyway. This is a deliberate trade-off: blocking indefinitely on an unresponsive follower is worse for availability than the small risk of occasional data loss.
But it means there is a concrete, measurable window in which the write exists only on the leader's log. If the leader crashes inside that window, before any follower has caught up, the write is gone permanently, and the client who received 200 OK has no way of knowing.
The SemiSyncReplicator in kv-fabric implements this trap faithfully:
1case <-timer.C:
2 // ── THE TRAP FIRES HERE ──
3 //
4 // No follower acknowledged within the timeout.
5 // We return fellBack=true. The caller (Propose) returns success to the client.
6 //
7 // Right now:
8 // - The write is on the leader's log
9 // - The write is NOT on any follower's log
10 // - If the leader crashes in the next few hundred milliseconds, this write vanishes permanently
11 // - The client has no idea
12 s.recordFallback(logIndex, "timeout")
13 return false, true1case <-timer.C:
2 // ── THE TRAP FIRES HERE ──
3 //
4 // No follower acknowledged within the timeout.
5 // We return fellBack=true. The caller (Propose) returns success to the client.
6 //
7 // Right now:
8 // - The write is on the leader's log
9 // - The write is NOT on any follower's log
10 // - If the leader crashes in the next few hundred milliseconds, this write vanishes permanently
11 // - The client has no idea
12 s.recordFallback(logIndex, "timeout")
13 return false, trueThe scenario sets semi-sync timeout to , writes a key, crashes the leader, waits for a new leader, and reads the key. It is gone.
Signal: kv_fabric_semisync_fallback_total > 0 when a leader dies is a guarantee of data loss. Not a risk. A guarantee. WE must monitor it with an alert that fires immediately on any non-zero increment during a leadership change.
Lesson: if absolute durability is required, semi-sync with a fallback is the wrong tool. Raft's normal quorum commit - wait for a majority before returning success — provides durability without any fallback trap.
Scenario 2: The Double Booking (make scenario-booking)
The real incident: Booking.com engineering teams documented MySQL replication lag of ~ during a traffic spike. That lag window was all it took. A follower that was behind the leader was still serving stale seat availability data. Two users checked the same seat at the same time: both read "available" from the lagging follower, both submitted bookings, and both received confirmation. The cluster accepted both writes because neither write was invalid in isolation. One booking silently overwrote the other. Alice found out at the gate.
The failure mechanism: The root cause is not the replication lag itself because some lag is always present in any replicated system. The root cause is routing a consistency-critical read (an availability check) to a node that cannot guarantee it has the latest data.
When Alice booked first, her write committed on the leader and on one fast follower. The stale follower, however, was still behind. Bob's availability check landed there. The follower truthfully returned what it knew: "available", but what it knew was already out of date.
The scenario reproduces this by injecting of artificial delay on one follower's replication path:
1c.Proxy.AddRule(transport.ProxyRule{
2 ID: "booking-com-lag",
3 FromNode: leader.ID,
4 ToNode: staleFollower.ID,
5 Action: transport.ActionDelay,
6 Params: map[string]interface{}{"delay_ms": 340},
7})1c.Proxy.AddRule(transport.ProxyRule{
2 ID: "booking-com-lag",
3 FromNode: leader.ID,
4 ToNode: staleFollower.ID,
5 Action: transport.ActionDelay,
6 Params: map[string]interface{}{"delay_ms": 340},
7})Alice's write commits via the leader and the fast follower (quorum of two). The stale follower's AppendEntries for Alice's booking is still sitting in the proxy delay queue. Bob reads from the stale follower: it shows "available". Bob books the seat. Both writes commit independently. Double booking confirmed.
The two fixes and why one is usually better:
Fix A: Strong read: Route the availability check through X-Consistency: strong. The ReadIndex protocol forces the serving node to confirm it is still the leader before answering, so it always sees Alice's booking. Stale data is structurally impossible. But the cost is that every availability check goes to the leader, which becomes a bottleneck under high traffic.
Fix B: Optimistic locking (CAS write): Include the version the client read when submitting the booking, via PutOptions{IfVersion: v}. The engine checks whether the seat's version has changed since the client last read it. Alice books first, her write succeeds and advances the version.
When Bob's booking arrives, the engine sees the current version no longer matches the version Bob read. The write is rejected with a conflict error. Bob retries, reads the updated status, sees the seat is taken, and picks a different one.
Fix B is generally the better choice for inventory systems. Fix A concentrates all availability reads on a single leader node: under peak traffic this becomes a hot spot. Fix B keeps reads eventual and distributed across all followers, paying a retry only when two clients collide on the exact same seat at the exact same moment, which, in practice, is a rare event.
Lesson: The answer to the double-booking problem is not "use strong consistency everywhere." It is "identify the specific reads where staleness has real consequences, and apply either a strong read or a CAS write to those operations. Nothing else needs to change."
Scenario 3: The MVCC Memory Leak (make scenario-mvcc-bloat)
The real incident: Long-running analytics queries in Postgres, MySQL InnoDB, and CockroachDB hold their transaction snapshot open indefinitely. The MVCC garbage collector cannot reclaim any version newer than the active transaction's snapshot. Version chains grow without bound. Memory and disk usage creep upward until the process hits limits. This is one of the most common sources of unexplained OOM events in production database clusters.
The scenario runs in three phases:
- Write versions of a hot key in a tight loop.
- Start an analytics transaction that pins version (simulating a long-running aggregate query).
- Keep writing. Watch:
kv_fabric_mvcc_gc_blocked=1. GC cannot advance past version 300 even as the commit index reaches . Versions accumulate in memory. - Finish the analytics job, unpin. GC reclaims versions 300–489 in a single pass.
The pin mechanism:
1func (e *MVCCEngine) PinVersion(key string, version uint64) {
2 chain.mu.Lock()
3 defer chain.mu.Unlock()
4 // Track the oldest pin. GC is blocked by the oldest active transaction.
5 if chain.pinned == 0 || version < chain.pinned {
6 chain.pinned = version
7 }
8}1func (e *MVCCEngine) PinVersion(key string, version uint64) {
2 chain.mu.Lock()
3 defer chain.mu.Unlock()
4 // Track the oldest pin. GC is blocked by the oldest active transaction.
5 if chain.pinned == 0 || version < chain.pinned {
6 chain.pinned = version
7 }
8}The observable surface: kv_fabric_mvcc_gc_blocked=1 in Prometheus is the signal. TotalVersions / TotalKeys > 10 is the bloat ratio to alert on. GCStats.OldestPinnedVersion tells us which version is blocking and lets you trace it back to which transaction is holding it.
Lesson: MVCC is not free. The price is that long-running transactions hold old versions hostage. The fix is a maximum transaction age enforced with a hard server-side timeout. If a transaction has been open for more than minutes, abort it. The depends on your GC interval and acceptable memory growth rate.
Scenario 4: The Dirty Read (make scenario-dirty-read)
The real incident: Any money transfer in a system without snapshot isolation. Let's say Alice has $1,000 and Bob has $1,000. A transaction transfers $200 from Alice to Bob. That transfer is not a single write but two sequential writes: debit Alice from $1,000 to $800, then credit Bob from $1,000 to $1,200. Between those two write operations, the total money in the system momentarily appears to be $1,800. If a concurrent reader lands in that gap, it sees a broken world.
Here is the exact sequence of events:
- Transfer starts: debit Alice → Alice is now $800
- Concurrent reader arrives here — reads Alice at $800, reads Bob at $1,000
- Transfer completes: credit Bob → Bob is now $1,200
The reader sees $800 + $1,000 = $1,800. Two hundred dollars have temporarily vanished from existence. This is a dirty read: the reader observed a partially-applied, internally inconsistent state.
// Without snapshot isolation: reader sees the intermediate state mid-transfer
aliceBalance, _ := engine.Get("account:alice", GetOptions{}) // $800 — already debited
bobBalance, _ := engine.Get("account:bob", GetOptions{}) // $1,000 — not yet credited
total := aliceBalance + bobBalance // $1,800: $200 has disappeared// Without snapshot isolation: reader sees the intermediate state mid-transfer
aliceBalance, _ := engine.Get("account:alice", GetOptions{}) // $800 — already debited
bobBalance, _ := engine.Get("account:bob", GetOptions{}) // $1,000 — not yet credited
total := aliceBalance + bobBalance // $1,800: $200 has disappearedThe fix: MVCC snapshot isolation
The solution is to give readers a stable version to read from: a snapshot of the world taken before the transfer started. In kv-fabric, GetAtVersion(key, maxVersion) does exactly this. It walks the version chain backward and returns the latest version with Num <= maxVersion, ignoring anything written after.
1// With MVCC snapshot isolation: reader pins a pre-transfer snapshot
2preTransferVersion := engine.CommitIndex() // capture the version before the transfer begins
3
4// ... transfer executes concurrently, writing new versions at higher indices ...
5
6aliceBalance, _ := engine.GetAtVersion("account:alice", preTransferVersion) // $1,000
7bobBalance, _ := engine.GetAtVersion("account:bob", preTransferVersion) // $1,000
8total := aliceBalance + bobBalance // $2,000: consistent, correct snapshot1// With MVCC snapshot isolation: reader pins a pre-transfer snapshot
2preTransferVersion := engine.CommitIndex() // capture the version before the transfer begins
3
4// ... transfer executes concurrently, writing new versions at higher indices ...
5
6aliceBalance, _ := engine.GetAtVersion("account:alice", preTransferVersion) // $1,000
7bobBalance, _ := engine.GetAtVersion("account:bob", preTransferVersion) // $1,000
8total := aliceBalance + bobBalance // $2,000: consistent, correct snapshotWhy does this work without holding any locks? Because MVCC versions are immutable once written. The transfer writes new versions at higher log indices, but the old versions - the ones preTransferVersion points to - are still there, untouched, in each key's version chain. The reader and the writer are operating on different versions of the same key simultaneously. No contention, no blocking.
Lesson: transactions exist to make multi-write operations appear atomic to concurrent readers. MVCC implements this without locking: readers and writers never block each other.
The cost of that property is version accumulation (Scenario 3). The discipline that follows: read transactions must have a maximum age, or old versions are pinned forever.
Three Gotchas and Nuances Worth Understanding
These are not hypothetical edge cases. They are the sharp edges that emerge when concurrent goroutines interact with buffered channels, locks, and incremental state — the kind of bugs that only appear under specific timing conditions and never in a single-threaded test. Each one is a lesson in Go concurrency that a textbook would not show you.
Gotcha 1: The Pre-Registration Race
Background: how client writes work
When a client sends a write, the Propose() function does two things:
- Submits the write to Raft and waits for the cluster to commit it.
- Blocks until a background goroutine (the "apply loop") signals that the write has been applied to the local engine.
The apply loop and Propose() communicate through a channel: Propose() creates a channel, puts it in a map (pending), and waits. The apply loop processes the committed entry, looks up the channel in the map, and sends the result. Propose() wakes up and returns.
The problem
For this handoff to work, the channel must be in the map before the apply loop looks for it. The original code inserted the channel after submitting to Raft:
1// BROKEN: registers AFTER proposing to Raft
2index, err := l.raft.Propose(ctx, data)
3// ← apply loop can process the committed entry RIGHT HERE
4l.pendingMu.Lock()
5l.pending[index] = &pendingOp{result: resultCh} // too late — apply loop already ran
6l.pendingMu.Unlock()
7// resultCh will never receive a value — Propose() blocks until timeout1// BROKEN: registers AFTER proposing to Raft
2index, err := l.raft.Propose(ctx, data)
3// ← apply loop can process the committed entry RIGHT HERE
4l.pendingMu.Lock()
5l.pending[index] = &pendingOp{result: resultCh} // too late — apply loop already ran
6l.pendingMu.Unlock()
7// resultCh will never receive a value — Propose() blocks until timeoutWhy can the apply loop run before Propose() returns? Because Raftly's commit channel is buffered. A buffered channel can hold items without anyone reading them, so Raft can push the committed entry into the channel immediately after quorum commits — without waiting for Propose() to finish. Under fast network conditions, the apply loop processes the entry before the pending map is updated. The client write hangs forever.
Fix: register first, then propose
1// FIXED: register the channel BEFORE submitting to Raft
2resultCh := make(chan applyResult, 1)
3reqID := fmt.Sprintf("%p", resultCh) // channel's memory address — unique per call
4op.RequestID = reqID
5
6l.pendingMu.Lock()
7l.pending[reqID] = &pendingOp{result: resultCh}
8l.pendingMu.Unlock()
9
10index, err := l.raft.Propose(ctx, data) // safe now: the channel is already registered1// FIXED: register the channel BEFORE submitting to Raft
2resultCh := make(chan applyResult, 1)
3reqID := fmt.Sprintf("%p", resultCh) // channel's memory address — unique per call
4op.RequestID = reqID
5
6l.pendingMu.Lock()
7l.pending[reqID] = &pendingOp{result: resultCh}
8l.pendingMu.Unlock()
9
10index, err := l.raft.Propose(ctx, data) // safe now: the channel is already registeredThe RequestID (the channel's memory address as a string) travels through the Raft log embedded in the operation. When the apply loop processes the entry, it reads the RequestID, finds the channel in the map, and sends the result. Order is now guaranteed: the channel is always registered before the apply loop could possibly look for it.
The rule this encodes: when two goroutines coordinate through a shared data structure, the receiver must be registered before the sender can fire. Pre-registration eliminates the race entirely — no locks, no retries, no polling.
Gotcha 2: The Deadlock
Background: what a mutex does
A mutex (sync.Mutex) is a lock. Only one goroutine can hold it at a time. If goroutine A holds the lock, goroutine B calling .Lock() will pause and wait until A calls .Unlock(). This is how you prevent two goroutines from corrupting shared data at the same time.
A deadlock happens when two goroutines are each waiting for the other to release a lock — and neither can proceed. The program does not crash. It does not print an error. It just stops doing anything. CPU drops to zero.
The problem
After the pre-registration fix, both the pending map write and the raft.Propose() call were wrapped inside the same lock:
// BROKEN: holding pendingMu for the entire duration of Propose()
l.pendingMu.Lock()
l.pending[reqID] = &pendingOp{result: resultCh}
index, err := l.raft.Propose(ctx, data) // ← this blocks waiting for the apply loop
l.pendingMu.Unlock()// BROKEN: holding pendingMu for the entire duration of Propose()
l.pendingMu.Lock()
l.pending[reqID] = &pendingOp{result: resultCh}
index, err := l.raft.Propose(ctx, data) // ← this blocks waiting for the apply loop
l.pendingMu.Unlock()Here is the chain of events that causes the deadlock:
- Goroutine A (client handler) acquires
pendingMuand callsraft.Propose().Propose()blocks internally, waiting for the Raft commit channel. - Raft commits the entry and pushes it to the apply loop.
- Goroutine B (apply loop) processes the entry and tries to notify the client — which means it tries to acquire
pendingMuto look up the channel. - Goroutine B blocks:
pendingMuis held by goroutine A. - Goroutine A blocks: it is waiting for the apply loop to signal it, but the apply loop is blocked waiting for the lock goroutine A holds.
Both goroutines are waiting on each other. Neither will ever proceed. Go's runtime deadlock detector does not fire here because other goroutines (metric collectors, tickers) are still running — the detector only fires when every goroutine is blocked. The server stays alive with zero useful CPU.
Fx: narrow the lock scope
1// FIXED: release the lock before calling Propose()
2l.pendingMu.Lock()
3l.pending[reqID] = &pendingOp{result: resultCh}
4l.pendingMu.Unlock() // ← unlock immediately after the map write
5
6index, err := l.raft.Propose(ctx, data) // lock is free; apply loop can acquire it1// FIXED: release the lock before calling Propose()
2l.pendingMu.Lock()
3l.pending[reqID] = &pendingOp{result: resultCh}
4l.pendingMu.Unlock() // ← unlock immediately after the map write
5
6index, err := l.raft.Propose(ctx, data) // lock is free; apply loop can acquire itRelease the lock as soon as the map write is done. The apply loop can now acquire pendingMu freely, find the channel, and send the result. Propose() unblocks and returns.
The rule this encodes: never hold a lock while calling a function that might need the same lock — directly or through any call chain. Lock scope should be as narrow as possible, wrapping only the data access it is protecting, nothing else.
Gotcha 3: The Snapshot Version Zero
Background: why snapshots need version numbers
A snapshot is a compact image of the entire key-value store at a point in time. Its purpose is to speed up node restarts: instead of replaying the entire Raft log from the beginning, a node loads the snapshot and replays only the entries that came after the snapshot was taken.
For that to work, the replication layer needs to know what the snapshot covers: "this snapshot contains everything up to log index , so start replay from ." That number — — is the snapshot's version. If it is wrong, the node cannot determine what to replay.
The problem
The snapshot version was set to gcHorizon: the log index up to which garbage collection had last run. At first glance this seems reasonable: GC only runs after data is safely replicated, so gcHorizon represents a stable point in history.
The problem is timing. GC runs on a 10-minute ticker. A freshly started node processes thousands of entries before GC has had its first chance to run. During that entire window, gcHorizon = 0.
// BROKEN: version is 0 if GC hasn't fired yet
snap.Version = e.gcHorizon // 0 if GC ticker hasn't ticked// BROKEN: version is 0 if GC hasn't fired yet
snap.Version = e.gcHorizon // 0 if GC ticker hasn't tickedA snapshot taken before the first GC run has version 0. On restart, the replication layer looks at the snapshot, sees version 0, concludes the snapshot covers nothing, and replays the entire log from the beginning — ignoring the snapshot entirely. The more entries the cluster has processed, the longer the restart takes.
The fix: derive the version from the snapshot's actual contents
1// FIXED: version = the highest log index present in the snapshot
2maxVer := e.gcHorizon
3for _, entry := range snap.Entries {
4 if entry.Version > maxVer {
5 maxVer = entry.Version
6 }
7}
8snap.Version = maxVer1// FIXED: version = the highest log index present in the snapshot
2maxVer := e.gcHorizon
3for _, entry := range snap.Entries {
4 if entry.Version > maxVer {
5 maxVer = entry.Version
6 }
7}
8snap.Version = maxVerWalk every key captured in the snapshot and find the highest version number among them. That is the true high-water mark of the snapshot: "this snapshot contains every write up to and including this index." A snapshot taken at log index now correctly reports version , regardless of whether GC has run.
On restart, the node loads the snapshot, sets its appliedIndex to , and asks Raft for entries starting at . For a cluster that has processed entries with hourly snapshots, restart time drops from "replay all entries" to "replay the ~ entries since the last snapshot."
The rule this encodes: a version number must reflect what actually exists in the data, not when some background process last ran. Background processes run on their own schedule; the data's contents are a fact.
Benchmark Lessons: The Numbers Are Surprising
The command make bench runs all four consistency modes across five workloads (write-only, read-heavy, mixed, read-your-writes, monotonic-watermark) at four concurrency levels (, , , goroutines) and produces a Markdown table with ops/sec, p50/p99 latency, and stale-read percentage.
A few results stand out:
Consistency mode does not affect write throughput. All four modes produce identical ops/sec on write-only workloads. The consistency mode is a read-side contract. All writes go through the same Raft propose path regardless of mode. If someone is arguing that "switching to eventual will speed up our writes," they are looking at the wrong layer.
The ReadIndex overhead is measurable but not catastrophic on a LAN. In read-heavy workloads, strong reads add 1–3ms versus eventual. This is the ConfirmLeadership round-trip overhead. On a LAN cluster with sub-millisecond RTT, it is noticeable but not prohibitive. Across availability zones at 5–10ms RTT, it becomes significant. Strong reads route all read traffic to the leader — at high read/write ratios, the leader becomes the bottleneck before latency does.
RYW and monotonic reads converge with strong under write pressure. When writes arrive fast enough to keep followers perpetually behind their watermarks, every RYW and monotonic read falls back to the leader — because every follower's appliedIndex is always below the client's required version. Throughput matches strong. This is the correct behavior (failing safe rather than serving stale data), but it is an important operational insight: session consistency modes look free until follower lag grows consistently positive.
stale% in eventual reads is the number to show your product team. In write-heavy workloads, eventual reads hit a 15–40% stale read rate with up to 500ms of lag at the tail. This is not always a problem — profile pictures, user preferences, and recommendation feeds can tolerate it. But when you show this number alongside a list of operations that currently use eventual reads, some of them will visibly not belong there.
What This Taught Me
Building kv-fabric confirmed something I suspected but could not quantify before: consistency is almost never a binary choice, and treating it as one is expensive in one direction or another.
The cost of implementing the spectrum is not large. The Router is 50 lines. Each reader is 50–80 lines. The session token implementation is 40 lines. The mechanism is not complex. What is complex is deciding, for each read path in our system, which guarantee it actually needs — and being able to defend that decision with data.
The benchmark gives us that data. The scenarios give us a concrete way to have the conversation. Instead of "we use eventual consistency for performance," we can say: "here is what happened to Booking.com with replication lag, here is the double booking, here is how we prevent it for this specific operation with a CAS write, and here is why we keep everything else eventual."
Do check out the README.md of the project to run and understand various scenarios.
Consistency is not magic. It is a trade-off with a price tag. Once we have measured it — per operation, under load — the right choice usually becomes obvious.
Namaste!
The Main Thread
I write a weekly deep dive like this one on distributed systems and AI engineering. One issue every week, straight to your inbox.
References
- Diego Ongaro, John Ousterhout — In Search of an Understandable Consensus Algorithm (Raft paper)
- Doug Terry et al. — Session Guarantees for Weakly Consistent Replicated Data
- Martin Kleppmann — Designing Data-Intensive Applications
- James C. Corbett et al. — Spanner: Google's Globally-Distributed Database
- Amazon Web Services — Summary of the Amazon Kinesis Event in the Northern Virginia (US-EAST-1) Region
- PostgreSQL Documentation — Chapter 13: Concurrency Control (MVCC)
Written by Anirudh Sharma
Published on April 28, 2026