Raftly: Building a Production-Grade Raft Implementation from Scratch
{A}Table of Contents
On April 21, 2011, Amazon's US-East-1 region fell over.
During a routine capacity upgrade, a network configuration change accidentally routed EBS control plane traffic to a backup network — one that wasn't designed to carry that load.
Thousands of EBS storage nodes suddenly lost contact with their replicas. Every one of them tried to re-sync at the same time, flooding the control plane with requests. The control plane couldn't keep up. RDS databases backed by EBS started failing too. The cascade lasted more than three days.
The public post-mortem AWS published afterward is still one of the best documents ever written about what happens when a distributed system meets a partial network failure at scale.
When I first read that post-mortem, I felt uncomfortable. I had read the Raft paper. I had watched the MIT 6.824 lectures. I had implemented enough of a single-node Raft to convince myself I understood it. But I could not trace the 2011 incident through the mental model I had built.
I had an understanding of what Raft did but I didn't quite fully understand what it defended against.
Knowing an algorithm and knowing its failure envelope are two vastly different skills. We can learn about an algorithm and its working in books but under what conditions, it fails can only be learned by breaking things.
So I built Raftly: a production-quality Raft implementation in Go whose primary purpose is to fail, repeatedly, in reproducible ways that reproduce incidents that actually happened in production systems — and then to recover from them.
Most distributed systems articles talk about the happy path. Raftly is a laboratory for the unhappy path.
This post is the story of what I built, what I broke, and what I learned.
The Problem With Reading Papers
The Raft paper is a masterpiece of clarity. Ongaro and Ousterhout wrote it specifically as a reaction to Paxos being too hard to reason about. They succeeded. The paper defines state transitions, safety invariants, and the log-matching property so clearly that any competent engineer can implement it in a weekend.
That's the problem.
When the algorithm is clear enough to implement in a weekend, the illusion of understanding comes cheaply. We run our implementation, three nodes elect a leader, we write some entries, they replicate, and we think: "I understand consensus now."
Then we try to answer questions like:
- What happens if the leader is partitioned from a minority but still accepts writes?
- If a follower is slow and a new leader is elected, can a committed entry be lost?
- If
fsyncreturns but the OS crashed before flushing, what's in our WAL? - If two nodes both believe they are leader during a partition, which one's writes survive?
- Why does adding pre-vote to Raft eliminate an entire class of availability bugs?
It is very hard to have satisfying answers to these just by reading. It is necessary for us to see them happen in a controlled environment where we can pause time, inspect state, and mutate the network.
What Is Raftly?
Raftly is a complete Raft consensus implementation in Go. It is not a toy. It implements the full algorithm including leader election, log replication, pre-vote, fast log backtracking, WAL-backed durability, and wraps it in a production-shaped shell: a gRPC transport layer, an HTTP key-value API, Prometheus metrics, and a configurable fault-injection proxy.
The goal is to use it as a laboratory: to reproduce real failure modes from real incidents in a small, fully observable system, and to understand why each defense in the algorithm exists by watching what happens when you remove it.
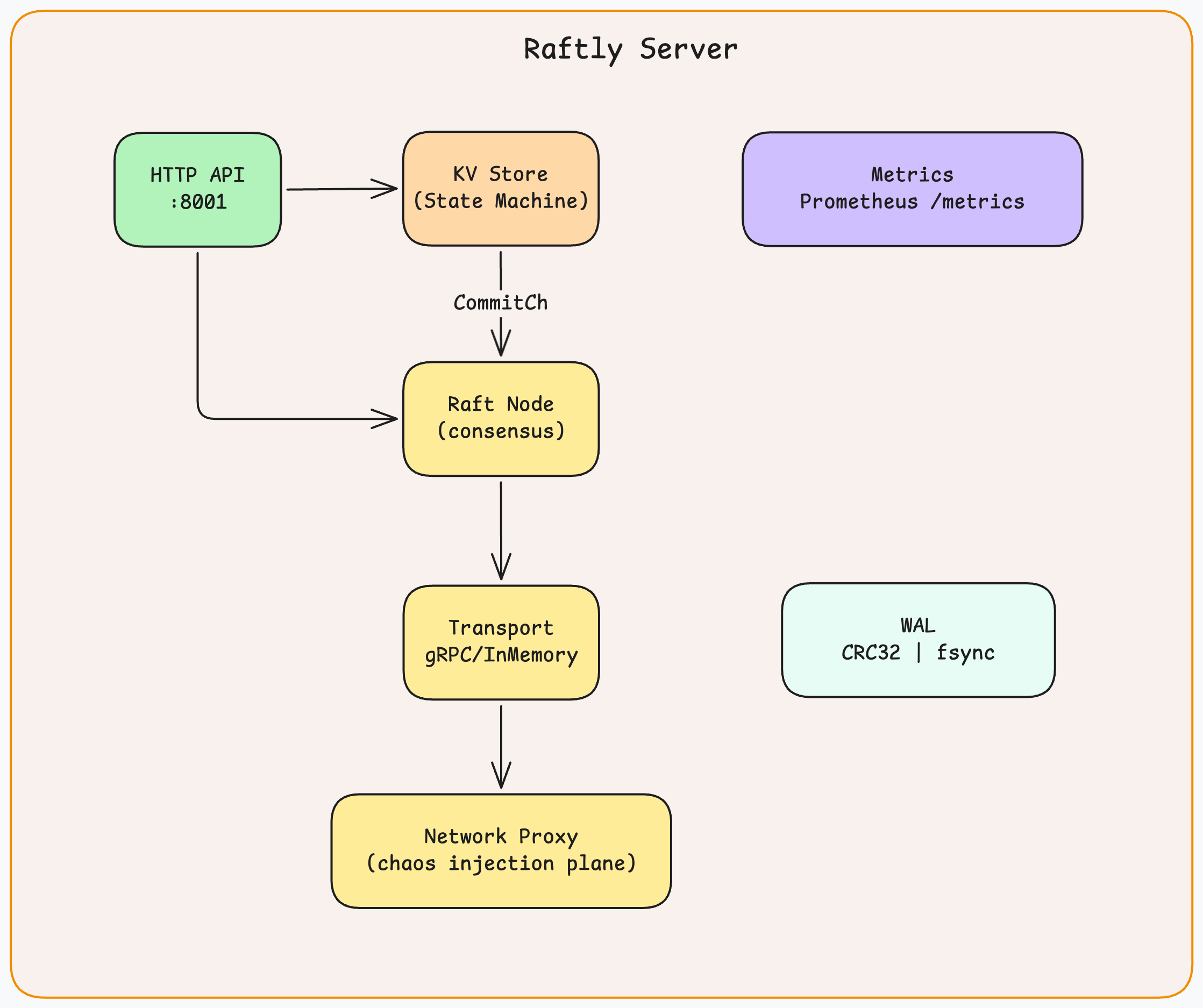
The Layered Architecture
Raftly is organized into four layers with clean interfaces between them. No layer knows more than it needs to about its neighbors.
 Zoom
Zoom
Each layer has one job:
- Transport sends and receives RPCs between nodes. The
Transportinterface means the entire Raft core can run against an in-memory transport in tests and against gRPC in production, without changing a line of consensus code. - Consensus is the Raft state machine. It drives elections, replication, and state transitions. It never inspects the content of log entries; it only moves them through the commit pipeline.
- Storage is split in two: the WAL is the source of truth (durable on disk), and the in-memory
RaftLogis a derived view rebuilt from WAL on every restart. - Application consumes committed entries from
commitChand applies them to a key-value map. It knows nothing about Raft internals — it only sees a stream of committedLogEntryvalues.
How a write flows end-to-end — from client call to 200 OK:
1client → PUT /keys/city
2 → KVStore.HandlePut()
3 → RaftNode.Propose(data)
4 → WAL.SaveEntry() + WAL.Sync() ← durable before anything else
5 → log.Append() ← in-memory, always after WAL
6 → maybeSendHeartbeats() ← triggers AppendEntries immediately
7 → wait on resultCh
8 ← AppendEntries reaches quorum
9 ← CommitTo(index)
10 ← notifyProposal(index) ← unblocks Propose()
11 → read from CommitCh
12 → apply to data map
13→ 200 OK1client → PUT /keys/city
2 → KVStore.HandlePut()
3 → RaftNode.Propose(data)
4 → WAL.SaveEntry() + WAL.Sync() ← durable before anything else
5 → log.Append() ← in-memory, always after WAL
6 → maybeSendHeartbeats() ← triggers AppendEntries immediately
7 → wait on resultCh
8 ← AppendEntries reaches quorum
9 ← CommitTo(index)
10 ← notifyProposal(index) ← unblocks Propose()
11 → read from CommitCh
12 → apply to data map
13→ 200 OKEvery step in this chain has a strict ordering. Reorder any two adjacent steps and you either lose durability or break the commit guarantee.
The Transport interface that decouples the consensus core from the network:
1type Transport interface {
2 SendRequestVote(ctx context.Context, peerID string, req VoteRequest) (VoteResponse, error)
3 SendPreVote(ctx context.Context, peerID string, req VoteRequest) (VoteResponse, error)
4 SendAppendEntries(ctx context.Context, peerID string, req AppendEntriesRequest) (AppendEntriesResponse, error)
5 Register(node *RaftNode)
6 Close() error
7}1type Transport interface {
2 SendRequestVote(ctx context.Context, peerID string, req VoteRequest) (VoteResponse, error)
3 SendPreVote(ctx context.Context, peerID string, req VoteRequest) (VoteResponse, error)
4 SendAppendEntries(ctx context.Context, peerID string, req AppendEntriesRequest) (AppendEntriesResponse, error)
5 Register(node *RaftNode)
6 Close() error
7}And the Config struct that controls every timing parameter:
1type Config struct {
2 NodeID string
3 Peers []PeerConfig
4 ElectionTimeout time.Duration // randomized between this and 2× — default 150ms
5 HeartbeatInterval time.Duration // leader sends this often — default 50ms
6 MaxLogEntries int
7 SnapshotThreshold int
8 DataDir string // WAL directory — e.g. data/node1
9 EnablePreVote bool // default true
10}1type Config struct {
2 NodeID string
3 Peers []PeerConfig
4 ElectionTimeout time.Duration // randomized between this and 2× — default 150ms
5 HeartbeatInterval time.Duration // leader sends this often — default 50ms
6 MaxLogEntries int
7 SnapshotThreshold int
8 DataDir string // WAL directory — e.g. data/node1
9 EnablePreVote bool // default true
10}The ElectionTimeout of 150ms and HeartbeatInterval of 50ms give a 3:1 ratio: the leader sends three heartbeats per election timeout. This means a slow heartbeat or two won't trigger an unnecessary election, but a crashed leader is detected within one timeout window.
Go through the README of the project for how to run and more details.
Raft Concepts: A Quick Primer
The rest of this post references Raft terms and RPC names frequently. If you have read the paper, this is a one-minute refresh. If you haven't, this is everything you need to follow along.
The Building Blocks
Log Entry: the atomic unit of data in Raft. Every client write becomes exactly one log entry. It carries four fields:
1type LogEntry struct {
2 Index uint64 // 1-based position in the log. Always increases.
3 Term uint64 // which leader era this entry was created in
4 Type EntryType // EntryNormal (data) or EntryConfig (membership change)
5 Data []byte // the raw command — e.g. {"op":"put","key":"city","value":"Bengaluru"}
6}1type LogEntry struct {
2 Index uint64 // 1-based position in the log. Always increases.
3 Term uint64 // which leader era this entry was created in
4 Type EntryType // EntryNormal (data) or EntryConfig (membership change)
5 Data []byte // the raw command — e.g. {"op":"put","key":"city","value":"Bengaluru"}
6}Term: Raft's logical clock. A monotonically increasing integer. Every election starts a new term. Every RPC carries the sender's term. If you see a higher term, you update yours and step down. Terms are the primary weapon against stale leaders: a message from term 3 is automatically rejected by a node that has advanced to term 7.
Node State — a node is always in one of four states:
| State | What it does |
|---|---|
Follower | Passive replica. Accepts entries from the leader. Votes in elections. |
Candidate | Running for leader. Has started an election and is collecting votes. |
PreCandidate | Running a dry-run election (pre-vote). Does not increment term. |
Leader | Drives all writes. Sends heartbeats. Replicates entries to followers. |
Commit Index: the highest log index known to be committed. An entry is committed when a majority of nodes have it in their logs. Once committed, an entry is permanent, it will never be removed or overwritten.
Applied Index: the highest log index that has been applied to the state machine (the key-value map). Always ≤ commitIndex. The gap between the two is the apply backlog: entries committed but not yet applied.
Quorum: . For a 3-node cluster: 2. For a 5-node cluster: 3. Both winning an election and committing an entry require a quorum. This is the single mathematical fact that prevents split-brain: two different quorums in a cluster of N nodes always share at least one member.
The Four RPCs
Raft nodes talk to each other using exactly four RPC types. Understanding what each one does makes the failure scenarios much easier to follow.
AppendEntries: the most frequent message in a healthy cluster. Sent by the leader to all followers every heartbeat interval (50ms in Raftly). When Entries is empty, it is a heartbeat, it resets the follower's election timer and tells it the leader is still alive. When Entries is non-empty, it replicates log entries. It also carries LeaderCommit so followers can advance their own commit index.
1type AppendEntriesRequest struct {
2 Term uint64 // leader's current term
3 LeaderID string // so followers know who to proxy client writes to
4 PrevLogIndex uint64 // index of the entry immediately before the new ones
5 PrevLogTerm uint64 // term at PrevLogIndex — follower rejects if this doesn't match
6 Entries []LogEntry // empty = heartbeat
7 LeaderCommit uint64 // leader's commit index — follower advances its own to this
8}1type AppendEntriesRequest struct {
2 Term uint64 // leader's current term
3 LeaderID string // so followers know who to proxy client writes to
4 PrevLogIndex uint64 // index of the entry immediately before the new ones
5 PrevLogTerm uint64 // term at PrevLogIndex — follower rejects if this doesn't match
6 Entries []LogEntry // empty = heartbeat
7 LeaderCommit uint64 // leader's commit index — follower advances its own to this
8}RequestVote: sent by a Candidate to collect votes. A node grants its vote only if two conditions are both true: it hasn't already voted for someone else in this term, and the candidate's log is at least as up-to-date as its own. The second condition is the election restriction, the safety mechanism that prevents a node with a stale log from winning an election and overwriting committed entries.
PreVote: — identical fields to RequestVote, but the receiver does not update any state. It answers a hypothetical: "if a real election started in term+1, would you vote for me?" Used before starting a real election to avoid disrupting the cluster if a quorum wouldn't vote for us anyway.
InstallSnapshot: — sent by the leader to bring a very lagging follower up to date in one shot instead of replaying hundreds of log entries. Raftly does not implement this (snapshots are out of scope), but it is the fifth Raft RPC for completeness.
Commit vs. Apply: The Two-Step Pipeline
These two concepts are often conflated and the distinction matters:
- Commit happens at the Raft layer. An entry is committed when the leader receives acknowledgments from a quorum of followers. The leader advances
commitIndex, and followers advance theirs when they hear about it via the nextLeaderCommitin anAppendEntries. - Apply happens at the application layer. After an entry is committed, it is sent to the state machine (the KV store) via
commitCh. The state machine executes the command and advanceslastApplied.
A client's write is not done until the entry is both committed (Raft guarantees it won't be lost) and applied (the state machine reflects it). Propose() in Raftly blocks until the entry is committed, which guarantees apply happens shortly after.
The Problem Raft Solves
Before explaining what Raft does, it is worth being precise about the problem it solves because the problem is stranger than it first appears.
Let's say we have N machines and we want them to agree on a sequence of values (replicated log). Each machine applies log entries to its own state machine in order. If all machines apply the same entries in the same order, they remain in sync. Clients can talk to any of them and get same answers.
This seems straightforward. It is not.
The difficulty is partial failure. In a distributed system, a node can be slow, partitioned (disconnected), or crashed. A message can be delayed, duplicated, or dropped. And crucially: we cannot distinguish a slow node from a crashed node. There is no global clock that tells us "node 2 is dead." Node 2 might just be experiencing a 2-second GC pause.
This leads directly to a result known as the FLP impossibility theorem (Fischer, Lynch, Paterson, 1985): in an asynchronous network where even one process can fail, no deterministic consensus algorithm can guarantee both safety (all processes agree on the same value) and liveness (the algorithm eventually terminates).
Raft has made its peace with it by not solving the unsolvable. It makes a trade-off: favour safety over liveness. The cluster of nodes may stop making progress during a partition (liveness is sacrificed) but it will never return conflicting answers (safety is maintained). When the partition heals, progress continues.
Everything else in Raft (terms, leader election rules, the commit condition, the vote restriction) follows this single design decision.
Raft's Core Idea: Strong Leader
Raft differs from Paxos in one fundamental way: it elects a single strong leader and routes all writes through it. The leader is the single source of truth. Followers are passive replicas that accept whatever the leader sends.
This simplifies reasoning enormously. We don't need to reconcile competing proposals from multiple nodes. The leader imposes a total order on all log entries. Followers either agree or they are told they are wrong.
As many of you noticed that this makes the leader a single point of failure. Raft handles this with leader election: if the leader dies, another leader is elected within the timeout.
Terms: The Distributed System's Logical Clock
Raft uses terms as its logical clock. A term is a monotonically increasing integer. Every node tracks the current term. When a node sees a message from a higher term, it immediately updates its own term and steps down to follower if it was a leader or candidate.
1type RaftNode struct {
2 currentTerm uint64 // durable — must survive crashes
3 votedFor string // durable — must survive crashes
4 state NodeState
5 leaderID string
6 ...
7}1type RaftNode struct {
2 currentTerm uint64 // durable — must survive crashes
3 votedFor string // durable — must survive crashes
4 state NodeState
5 leaderID string
6 ...
7}The currentTerm and votedFor fields are marked durable in the comments. This is a strict invariant and not just a decoration. These two fields must be written to the Write-Ahead Log (WAL) before replying to any RPC. If we crash between writing and replying, we simply don't reply. The peer retries and gets a consistent answer. This approach makes it safe.
Terms serve as a protection mechanism. A message from term 3 is automatically ignored by a node that has advanced to term 5. This is how Raft handles the "zombie leader" scenario: a leader that was partitioned away, missed elections, and is now trying to send AppendEntries to followers who have moved on.
In Raftly project, the term update is enforced at every RPC handler boundary:
1if req.Term > n.currentTerm {
2 n.becomeFollower(req.Term, "")
3}
4
5if req.Term < n.currentTerm {
6 return VoteResponse{Term: n.currentTerm, VoteGranted: false}
7}1if req.Term > n.currentTerm {
2 n.becomeFollower(req.Term, "")
3}
4
5if req.Term < n.currentTerm {
6 return VoteResponse{Term: n.currentTerm, VoteGranted: false}
7}And in becomeFollower:
1func (n *RaftNode) becomeFollower(term uint64, leaderID string) {
2 n.state = Follower
3 n.leaderID = leaderID
4
5 if term > n.currentTerm {
6 n.currentTerm = term
7 n.votedFor = ""
8 _ = n.wal.SaveState(term, "")
9 _ = n.wal.Sync()
10 }
11 ...
12}1func (n *RaftNode) becomeFollower(term uint64, leaderID string) {
2 n.state = Follower
3 n.leaderID = leaderID
4
5 if term > n.currentTerm {
6 n.currentTerm = term
7 n.votedFor = ""
8 _ = n.wal.SaveState(term, "")
9 _ = n.wal.Sync()
10 }
11 ...
12}The WAL write and sync happen before the function returns. If we acknowledge a higher term, that acknowledgment is durable before anything else happens.
Leader Election: Randomized Timeouts and the Vote Restriction
Every follower runs an election timer. When the timer fires without hearing from a leader, the follower starts an election. If a new leader is elected and begins sending heartbeats, all timers reset and the cluster stabilizes.
The timers are deliberately randomized:
func (n *RaftNode) randomElectionTimeout() time.Duration {
base := n.config.ElectionTimeout // 150ms in Raftly
jitter := time.Duration(rand.Int63n(int64(base)))
return base + jitter // uniformly in [150ms, 300ms)
}func (n *RaftNode) randomElectionTimeout() time.Duration {
base := n.config.ElectionTimeout // 150ms in Raftly
jitter := time.Duration(rand.Int63n(int64(base)))
return base + jitter // uniformly in [150ms, 300ms)
}Why random? Because if all followers had the same timeout, they would all fire simultaneously, all start elections at once, and split every vote indefinitely. Randomization means that in practice, one node fires slightly before the others and collects votes before anyone else starts competing.
When a candidate starts an election, it sends RequestVote RPCs to all peers in parallel:
1votes := 1 // self-vote
2needed := n.quorum()
3
4for range peers {
5 resp := <-voteCh
6 ...
7 if resp.VoteGranted {
8 votes++
9 }
10 if votes >= needed {
11 n.becomeLeader()
12 return
13 }
14}1votes := 1 // self-vote
2needed := n.quorum()
3
4for range peers {
5 resp := <-voteCh
6 ...
7 if resp.VoteGranted {
8 votes++
9 }
10 if votes >= needed {
11 n.becomeLeader()
12 return
13 }
14}The quorum() function returns floor(N/2) + 1. For a 3-node cluster, quorum is 2. For a 5-node cluster, it is 3. This majority requirement is what prevents split-brain: two nodes cannot simultaneously win an election in the same term, because there aren't enough votes for both.
The Vote Restriction: Keeping Committed Entries Safe
A node grants a vote to a candidate only if the candidate's log is at least up-to-date as the node's own log.
This is the most important part of leader election.
1func (n *RaftNode) isLogUpToDate(candidateLastTerm, candidateLastIndex uint64) bool {
2 myLastTerm := n.log.LastTerm()
3 myLastIndex := n.log.LastIndex()
4
5 if candidateLastTerm != myLastTerm {
6 return candidateLastTerm > myLastTerm
7 }
8 return candidateLastIndex >= myLastIndex
9}1func (n *RaftNode) isLogUpToDate(candidateLastTerm, candidateLastIndex uint64) bool {
2 myLastTerm := n.log.LastTerm()
3 myLastIndex := n.log.LastIndex()
4
5 if candidateLastTerm != myLastTerm {
6 return candidateLastTerm > myLastTerm
7 }
8 return candidateLastIndex >= myLastIndex
9}"Up-to-date" is defined precisely: compare the term of the last log entry first. A higher term wins. If terms are equal, the longer log wins.
Why does this matter? Consider this scenario:
- Node A is leader in term 1. It replicates entry
[index=5, term=1]to node B but not to node C before crashing. - Node C wins the election for term 2. But node B has entry 5. If B's vote is required to reach quorum, and B enforces the up-to-date check, then C can only win if C's log is at least as long as B's. C's log is shorter, so C cannot win.
- Only a node that has entry 5 can become the term-2 leader.
This is the Election Restriction from the Raft paper. By requiring a majority vote with a staleness check, Raft guarantees that the leader always has all committed entries. An entry is committed when a majority of nodes have it. A new leader must get votes from a majority. At least one node in any two majorities overlaps. That overlap node has the committed entry and will not vote for a candidate that is missing it.
Pre-Vote: Defending Against Disruptive Followers
Consider the following scenario: There is a cluster where node A is the leader. Suddenly, due to some issue, node C gets partitioned away but rest of the cluster is still running. Node C's timer keeps firing because it is not receiving any heartbeat from node A (leader), it starts elections and increments its term to 4, 5, 6,...
When C rejoins the cluster, it sends RequestVote with term 6. Node A receives it and see the higher term than its own term and decides to step down. Now, the cluster elects a new leader. This election was not needed at all because apart from node C, rest of the cluster was healthy.
It's pretty clear that with this approach every reconnection from a partitioned node can cause unnecessary re-elections and causes availability hiccup.
How to fix this?
The answer is Pre Vote, in which before starting a real election, a candidate asks peers, "if I started an election in term + 1, would you vote for me?" This is like a dry run.
If the cluster has an active leader, peers respond "no". The partitioned node cannot reach pre-vote quorum, so it never increments its term, and it cannot disrupt the cluster when it reconnects.
1func (n *RaftNode) handlePreVote(req VoteRequest) VoteResponse {
2 ...
3 // The core pre-vote defense:
4 // If we have an active leader, deny the pre-vote.
5 if n.leaderID != "" {
6 return VoteResponse{Term: n.currentTerm, VoteGranted: false}
7 }
8
9 // Same log up-to-date check as real election
10 if !n.isLogUpToDate(req.LastLogTerm, req.LastLogIndex) {
11 return VoteResponse{Term: n.currentTerm, VoteGranted: false}
12 }
13
14 return VoteResponse{Term: n.currentTerm, VoteGranted: true}
15}1func (n *RaftNode) handlePreVote(req VoteRequest) VoteResponse {
2 ...
3 // The core pre-vote defense:
4 // If we have an active leader, deny the pre-vote.
5 if n.leaderID != "" {
6 return VoteResponse{Term: n.currentTerm, VoteGranted: false}
7 }
8
9 // Same log up-to-date check as real election
10 if !n.isLogUpToDate(req.LastLogTerm, req.LastLogIndex) {
11 return VoteResponse{Term: n.currentTerm, VoteGranted: false}
12 }
13
14 return VoteResponse{Term: n.currentTerm, VoteGranted: true}
15}An important thing to remember is that pre-vote handlers do not update votedFor, do not update currentTerm, and do not write to the WAL because it is a hypothetical query, not a state change.
This is how we handle both phases. If pre-vote quorum is reached, it escalates to a real election.
1func (n *RaftNode) campaign(preVote bool) {
2 ...
3 if votes >= needed {
4 if preVote {
5 n.logger.Info("pre-vote won, escalating to election", ...)
6 n.campaign(false) // escalate to real election
7 } else {
8 n.logger.Info("election won", ...)
9 n.becomeLeader()
10 }
11 return
12 }
13}1func (n *RaftNode) campaign(preVote bool) {
2 ...
3 if votes >= needed {
4 if preVote {
5 n.logger.Info("pre-vote won, escalating to election", ...)
6 n.campaign(false) // escalate to real election
7 } else {
8 n.logger.Info("election won", ...)
9 n.becomeLeader()
10 }
11 return
12 }
13}Becoming Leader: The No-Op Entry
When a node wins an election, becomeLeader() function does something that surprises people the first time they see it:
1func (n *RaftNode) becomeLeader() {
2 n.state = Leader
3 n.leaderID = n.id
4
5 // Reset follower tracking
6 lastIndex := n.log.LastIndex()
7 for _, peer := range n.peers {
8 peer.NextIndex = lastIndex + 1
9 peer.MatchIndex = 0
10 }
11
12 // Append a no-op entry in the current term
13 noop := LogEntry{
14 Index: lastIndex + 1,
15 Term: n.currentTerm,
16 Type: EntryNormal,
17 Data: nil,
18 }
19 _ = n.wal.SaveEntry(noop)
20 _ = n.wal.Sync()
21 _ = n.log.Append([]LogEntry{noop})
22
23 go n.maybeSendHeartbeats()
24}1func (n *RaftNode) becomeLeader() {
2 n.state = Leader
3 n.leaderID = n.id
4
5 // Reset follower tracking
6 lastIndex := n.log.LastIndex()
7 for _, peer := range n.peers {
8 peer.NextIndex = lastIndex + 1
9 peer.MatchIndex = 0
10 }
11
12 // Append a no-op entry in the current term
13 noop := LogEntry{
14 Index: lastIndex + 1,
15 Term: n.currentTerm,
16 Type: EntryNormal,
17 Data: nil,
18 }
19 _ = n.wal.SaveEntry(noop)
20 _ = n.wal.Sync()
21 _ = n.log.Append([]LogEntry{noop})
22
23 go n.maybeSendHeartbeats()
24}The leader immediately appends and replicates a no-op entry in the current term. This is not ceremonial. It solves a real problem.
When a new leader is elected, it does not know the exact commit index of the previous leader. It knows its own log is at least as up-to-date as a majority (the vote restriction guarantees this), but there may be entries from previous terms that were replicated to a majority but never explicitly committed.
A leader can replicate an old-term entry to a majority, then crash before committing it. A new leader gets elected. Can the new leader commit that old entry? No — doing so can cause entries to be overwritten in certain election sequences.
The rule is: a leader never directly commits entries from previous terms. It only directly commits entries from the current term. Old entries become committed as a side effect when a current-term entry's commit index passes them.
if entry.Term != n.currentTerm {
return // do not directly commit old-term entries
}
_ = n.log.CommitTo(quorumMatchIndex)if entry.Term != n.currentTerm {
return // do not directly commit old-term entries
}
_ = n.log.CommitTo(quorumMatchIndex)The no-op entry creates a current-term entry immediately. Once that entry is replicated to a majority and committed, all preceding entries (from any previous term) are implicitly committed as a side effect. The new leader now knows the full commit state.
Log Replication: AppendEntries
Once a leader is elected, it "proposes" all writes to all followers.
1func (n *RaftNode) Propose(data []byte) (index uint64, term uint64, err error) {
2 n.mu.Lock()
3
4 if n.state != Leader {
5 leaderID := n.leaderID
6 n.mu.Unlock()
7 return 0, 0, fmt.Errorf("not leader, try: %s", leaderID)
8 }
9
10 entry := LogEntry{
11 Index: n.log.LastIndex() + 1,
12 Term: n.currentTerm,
13 Type: EntryNormal,
14 Data: data,
15 }
16
17 // Durability first: WAL before in-memory log
18 if err = n.wal.SaveEntry(entry); err != nil { // handle error }
19 if err = n.wal.Sync(); err != nil { // handle error }
20 if err = n.log.Append([]LogEntry{entry}); err != nil { // handle error }
21
22 go n.maybeSendHeartbeats() // trigger immediate replication
23
24 resultCh := make(chan proposeResult, 1)
25 n.proposals[entry.Index] = resultCh
26 n.mu.Unlock()
27
28 // Block until committed or node stops
29 select {
30 case result := <-resultCh:
31 return index, term, result.err
32 case <-n.stopCh:
33 return index, term, fmt.Errorf("node stopped")
34 }
35}1func (n *RaftNode) Propose(data []byte) (index uint64, term uint64, err error) {
2 n.mu.Lock()
3
4 if n.state != Leader {
5 leaderID := n.leaderID
6 n.mu.Unlock()
7 return 0, 0, fmt.Errorf("not leader, try: %s", leaderID)
8 }
9
10 entry := LogEntry{
11 Index: n.log.LastIndex() + 1,
12 Term: n.currentTerm,
13 Type: EntryNormal,
14 Data: data,
15 }
16
17 // Durability first: WAL before in-memory log
18 if err = n.wal.SaveEntry(entry); err != nil { // handle error }
19 if err = n.wal.Sync(); err != nil { // handle error }
20 if err = n.log.Append([]LogEntry{entry}); err != nil { // handle error }
21
22 go n.maybeSendHeartbeats() // trigger immediate replication
23
24 resultCh := make(chan proposeResult, 1)
25 n.proposals[entry.Index] = resultCh
26 n.mu.Unlock()
27
28 // Block until committed or node stops
29 select {
30 case result := <-resultCh:
31 return index, term, result.err
32 case <-n.stopCh:
33 return index, term, fmt.Errorf("node stopped")
34 }
35}First: the WAL write and sync happen before the entry is added to the in-memory log. This means the WAL is always the source of truth. If we crash after Sync() but before log.Append(), the entry is durable in the WAL and will be replayed into memory on restart. If we crash before Sync(), the CRC32 check discards the partial record and the entry is treated as if it was never written. Either way, the in-memory state is always reconstructable from the WAL.
Second: Propose() blocks until the entry is committed, not just written. The caller's resultCh is registered in n.proposals[entry.Index]. When applyCommitted() applies that entry, it calls notifyProposal(index, nil), which unblocks the waiting Propose(). Clients get a committed-or-error response — never a "maybe."
The Log Consistency Check
Every AppendEntries RPC carries two fields: PrevLogIndex and PrevLogTerm. Before the follower accepts any new entries, it verifies that its log matches the leader's at exactly that position:
1if req.PrevLogIndex > 0 {
2 prevEntry, err := n.log.GetEntry(req.PrevLogIndex)
3 if err != nil {
4 // Log is shorter than PrevLogIndex
5 return AppendEntriesResponse{
6 Term: n.currentTerm,
7 Success: false,
8 ConflictIndex: n.log.LastIndex() + 1,
9 ConflictTerm: 0,
10 }
11 }
12 if prevEntry.Term != req.PrevLogTerm {
13 // Term mismatch: fast backtracking
14 conflictTerm := prevEntry.Term
15 conflictIndex := req.PrevLogIndex
16 for conflictIndex > 1 {
17 entry, err := n.log.GetEntry(conflictIndex - 1)
18 if err != nil || entry.Term != conflictTerm {
19 break
20 }
21 conflictIndex--
22 }
23 return AppendEntriesResponse{
24 Term: n.currentTerm,
25 Success: false,
26 ConflictTerm: conflictTerm,
27 ConflictIndex: conflictIndex,
28 }
29 }
30}1if req.PrevLogIndex > 0 {
2 prevEntry, err := n.log.GetEntry(req.PrevLogIndex)
3 if err != nil {
4 // Log is shorter than PrevLogIndex
5 return AppendEntriesResponse{
6 Term: n.currentTerm,
7 Success: false,
8 ConflictIndex: n.log.LastIndex() + 1,
9 ConflictTerm: 0,
10 }
11 }
12 if prevEntry.Term != req.PrevLogTerm {
13 // Term mismatch: fast backtracking
14 conflictTerm := prevEntry.Term
15 conflictIndex := req.PrevLogIndex
16 for conflictIndex > 1 {
17 entry, err := n.log.GetEntry(conflictIndex - 1)
18 if err != nil || entry.Term != conflictTerm {
19 break
20 }
21 conflictIndex--
22 }
23 return AppendEntriesResponse{
24 Term: n.currentTerm,
25 Success: false,
26 ConflictTerm: conflictTerm,
27 ConflictIndex: conflictIndex,
28 }
29 }
30}This check enforces the Log Matching Property: if two logs have an entry at the same index with the same term, then the logs are identical in all entries up to and including that index. The leader only ever appends entries, and AppendEntries is rejected unless the prefix matches exactly. This is the inductive invariant that Raft maintains to make log divergence detectable and recoverable.
Fast Log Backtracking
In the naive Raft implementation, when a follower rejects AppendEntries because of a log conflict, the leader decrements nextIndex by 1 and retries. If a follower is 1000 entries behind, this takes 1000 round trips.
Clearly, this is not optimized. To tackle this, the follower reports the term of the conflicting entry and the first index at which that term appears. The leader can then skip back to just after its last entry in that term, resolving the conflict in a single retry.
1if resp.ConflictTerm > 0 {
2 newNextIndex := resp.ConflictTerm
3 for i := n.log.LastIndex(); i >= 1; i-- {
4 entry, err := n.log.GetEntry(i)
5 if err != nil {
6 break
7 }
8 if entry.Term == resp.ConflictTerm {
9 newNextIndex = i + 1
10 break
11 }
12 }
13 peer.NextIndex = newNextIndex
14} else {
15 // Follower's log is shorter — jump back to its last index
16 peer.NextIndex = resp.ConflictIndex
17}1if resp.ConflictTerm > 0 {
2 newNextIndex := resp.ConflictTerm
3 for i := n.log.LastIndex(); i >= 1; i-- {
4 entry, err := n.log.GetEntry(i)
5 if err != nil {
6 break
7 }
8 if entry.Term == resp.ConflictTerm {
9 newNextIndex = i + 1
10 break
11 }
12 }
13 peer.NextIndex = newNextIndex
14} else {
15 // Follower's log is shorter — jump back to its last index
16 peer.NextIndex = resp.ConflictIndex
17}The Commit Rule
After each successful AppendEntries response, the leader checks whether it can advance the commit index:
1matchIndexes := make([]uint64, 0, len(n.peers) + 1)
2matchIndexes = append(matchIndexes, n.log.LastIndex()) // leader counts itself
3for _, peer := range n.peers {
4 matchIndexes = append(matchIndexes, peer.MatchIndex)
5}
6
7sort.Slice(matchIndexes, func(i, j int) bool {
8 return matchIndexes[i] < matchIndexes[j]
9})
10quorumMatchIndex := matchIndexes[len(matchIndexes)-n.quorum()]1matchIndexes := make([]uint64, 0, len(n.peers) + 1)
2matchIndexes = append(matchIndexes, n.log.LastIndex()) // leader counts itself
3for _, peer := range n.peers {
4 matchIndexes = append(matchIndexes, peer.MatchIndex)
5}
6
7sort.Slice(matchIndexes, func(i, j int) bool {
8 return matchIndexes[i] < matchIndexes[j]
9})
10quorumMatchIndex := matchIndexes[len(matchIndexes)-n.quorum()]After sorting ascending, the entry at position len - quorum is the highest index that a majority of nodes have confirmed. For a 3-node cluster (quorum=2), matchIndexes has 3 elements; matchIndexes[3-2] = matchIndexes[1] is the second-lowest — the highest index held by at least 2 nodes.
Durability: The Write-Ahead Log
Every Raft implementation needs a WAL. Raftly's WAL implementation is a single append-only file with a deterministic binary format:
[ 4 bytes: record length ][ N bytes: record data ][ 4 bytes: CRC32 ][ 4 bytes: record length ][ N bytes: record data ][ 4 bytes: CRC32 ]There are two record types:
- State record:
currentTerm+votedFor. Written before every vote cast. - Entry record: a full
LogEntry. Written before every append acknowledgment.
1func (w *WAL) writeRecord(data []byte) error {
2 lenBuf := make([]byte, 4)
3 binary.BigEndian.PutUint32(lenBuf, uint32(len(data)))
4 w.writer.Write(lenBuf)
5 w.writer.Write(data)
6
7 checksum := crc32.ChecksumIEEE(data)
8 crcBuf := make([]byte, 4)
9 binary.BigEndian.PutUint32(crcBuf, checksum)
10 w.writer.Write(crcBuf)
11 return nil
12}1func (w *WAL) writeRecord(data []byte) error {
2 lenBuf := make([]byte, 4)
3 binary.BigEndian.PutUint32(lenBuf, uint32(len(data)))
4 w.writer.Write(lenBuf)
5 w.writer.Write(data)
6
7 checksum := crc32.ChecksumIEEE(data)
8 crcBuf := make([]byte, 4)
9 binary.BigEndian.PutUint32(crcBuf, checksum)
10 w.writer.Write(crcBuf)
11 return nil
12}The CRC32 is computed over the record data and appended at the end. On recovery, ReadAll() (below) verifies each record's checksum. If the checksum fails, it stops reading: it has hit a torn write boundary. Everything before that point is valid; everything after is discarded.
1// ReadAll()
2expected := binary.BigEndian.Uint32(crcBuf)
3actual := crc32.ChecksumIEEE(data)
4if expected != actual {
5 break // torn write detected — recovery boundary
6}1// ReadAll()
2expected := binary.BigEndian.Uint32(crcBuf)
3actual := crc32.ChecksumIEEE(data)
4if expected != actual {
5 break // torn write detected — recovery boundary
6}This is not paranoia. Power loss mid-write is a real scenario. Without CRC detection, a partial record could be decoded as valid data, corrupting the node's state on restart.
The fsync Discipline
There is a distinction between a write reaching the OS page cache and a write reaching physical media. write() goes to the page cache. fsync() flushes the page cache to disk. If the OS crashes between write() and fsync(), the write is lost.
Raftly's Sync() does both:
1func (w *WAL) Sync() error {
2 if err := w.writer.Flush(); err != nil { // flush bufio → OS
3 return err
4 }
5 return w.file.Sync() // OS page cache → disk
6}1func (w *WAL) Sync() error {
2 if err := w.writer.Flush(); err != nil { // flush bufio → OS
3 return err
4 }
5 return w.file.Sync() // OS page cache → disk
6}Sync() is called in exactly three places:
- After
SaveState(): before replying to any vote RPC - After
SaveEntry()on the leader: beforePropose()appends to memory - After
SaveEntries()on a follower: before sendingAppendEntriesACK
Skipping any one of these creates a durability hole. An entry could appear committed (the leader advanced its commit index, the client got a success response), but the WAL record was never "fsynced". After a crash, the entry disappears. The cluster has given a client a confirmed write that no longer exists.
The State Machine: Key-Value Store
The Raft layer produces a stream of committed LogEntry values on commitCh. The application layer: a KVStore: consumes this channel and applies each entry to a map[string]string:
1func (kv *KVStore) apply(entry raft.LogEntry) {
2 var cmd Command
3 if err := json.Unmarshal(entry.Data, &cmd); err != nil {
4 return // malformed — skip
5 }
6
7 kv.mu.Lock()
8 defer kv.mu.Unlock()
9
10 switch cmd.Op {
11 case "put":
12 kv.data[cmd.Key] = cmd.Value
13 case "delete":
14 delete(kv.data, cmd.Key)
15 }
16}1func (kv *KVStore) apply(entry raft.LogEntry) {
2 var cmd Command
3 if err := json.Unmarshal(entry.Data, &cmd); err != nil {
4 return // malformed — skip
5 }
6
7 kv.mu.Lock()
8 defer kv.mu.Unlock()
9
10 switch cmd.Op {
11 case "put":
12 kv.data[cmd.Key] = cmd.Value
13 case "delete":
14 delete(kv.data, cmd.Key)
15 }
16}This is the state machine. It is deterministic. Given the same sequence of log entries, every node that applies them will arrive at the same state. This is the fundamental correctness guarantee: as long as Raft ensures all nodes commit the same entries in the same order, the state machines stay in sync.
The KVStore exposes three HTTP endpoints: PUT /keys/{key}, GET /keys/{key}, and DELETE /keys/{key}. If a request arrives at a follower, the follower proxies it transparently to the current leader. The leader's address is tracked per node ID via the httpPeers map configured at startup.
Observability: Structured Logging and Prometheus
Every state transition in Raftly is logged using go.uber.org/zap:
1n.logger.Info("→ leader",
2 zap.Uint64("term", n.currentTerm),
3 zap.Uint64("log_index", n.log.LastIndex()),
4)
5
6n.logger.Info("vote granted",
7 zap.String("candidate", req.CandidateID),
8 zap.Uint64("term", req.Term),
9)
10
11n.logger.Warn("log conflict: truncating",
12 zap.Uint64("from_index", entry.Index),
13 zap.Uint64("local_term", existing.Term),
14 zap.Uint64("leader_term", entry.Term),
15)1n.logger.Info("→ leader",
2 zap.Uint64("term", n.currentTerm),
3 zap.Uint64("log_index", n.log.LastIndex()),
4)
5
6n.logger.Info("vote granted",
7 zap.String("candidate", req.CandidateID),
8 zap.Uint64("term", req.Term),
9)
10
11n.logger.Warn("log conflict: truncating",
12 zap.Uint64("from_index", entry.Index),
13 zap.Uint64("local_term", existing.Term),
14 zap.Uint64("leader_term", entry.Term),
15)Structured logging matters in distributed systems because we need to correlate events across three nodes simultaneously. JSON fields let us filter and aggregate across a cluster without parsing unstructured strings.
Prometheus metrics are exposed at /metrics on each node:
| Metric | Type | Meaning |
|---|---|---|
raftly_current_term | Gauge | Current Raft term |
raftly_state | Gauge | 0=follower, 1=candidate, 2=leader |
raftly_committed_index | Gauge | Highest committed log index |
raftly_applied_index | Gauge | Highest applied log index |
raftly_elections_total | Counter | Elections started by this node |
raftly_leader_changes_total | Counter | Leader changes observed |
raftly_wal_fsync_duration_ms | Histogram | WAL fsync latency |
raftly_replication_lag | Histogram | Per-peer replication lag (leader) |
The gap between committed_index and applied_index tells you the apply backlog. WAL fsync duration above 10ms is worth alarming on — at that latency, you're approaching your heartbeat interval (50ms) and election timeouts become tight.
The Failures: What I Deliberately Broke
The Raftly codebase includes a NetworkProxy layer with configurable fault-injection rules. I used this to simulate every failure mode I could think of — and a few I discovered only after the tests started failing.
The four key scenarios map to published incidents:
| Scenario | Real incident |
|---|---|
| Split Brain | AWS US-East-1 EBS failure, April 2011 |
| Stale Log Elected Leader | etcd election restriction bug pattern, 2018 |
| WAL Torn Write | Any process killed mid-fsync — universal |
| Disruptive Follower | Pre-vote absent in early Raft implementations |
Failure 1: Split-Brain and the Quorum Defense
The split-brain scenario: we elect a leader in a 3-node cluster, write ten entries, then partition the leader away from the other two nodes.
Without quorum, the isolated leader is stuck. It tries to replicate to followers it can no longer reach. Its AppendEntries RPCs time out. Its proposed entries never commit. From the isolated leader's perspective, writes are just hanging. Clients never get an acknowledgment.
Meanwhile, the two remaining followers notice they haven't heard from the leader in longer than the election timeout. One starts a new election, wins (2/3 votes = quorum), and becomes leader at a higher term.
When the partition heals, the old leader's next AppendEntries reaches a follower that is now in a higher-term cluster. The follower replies with the higher term. The old leader sees it and immediately steps down:
if resp.Term > n.currentTerm {
n.becomeFollower(resp.Term, "")
return
}if resp.Term > n.currentTerm {
n.becomeFollower(resp.Term, "")
return
}Three lines. That's the entire defense against split-brain.
The invariant that makes this safe is the commit rule: an entry is only committed once a majority of nodes have acknowledged it. The isolated leader never got quorum, so its hanging entries were never committed. Discarding them is lossless. No client ever got an acknowledgment for those writes. From the outside, they simply never happened.
This is the deep reason Raft requires a majority: not just to achieve agreement, but to guarantee that at most one leader can ever commit anything. If we require votes for both leadership and commit, then any two majorities must overlap by at least one node — and that node serves as the memory of what was committed.
Failure 2: Stale Log Elected Leader
A follower is partitioned from the cluster at log index 10. While partitioned, the rest of the cluster commits entries 11 through 20. The partition heals. Because election timeouts are randomized, the previously-partitioned node's timer fires first. It calls for an election.
If the election restriction is absent or buggy, the stale node can win. It has no knowledge of entries 11–20. If it becomes leader, those entries — which were committed by a previous majority — will be overwritten. This is data loss of committed data. It is one of the worst outcomes a distributed system can produce.
The defense is isLogUpToDate() inside handleRequestVote(). The up-to-date followers (at index 20) look at the candidate's claimed LastLogIndex = 10 and refuse. The stale node cannot win a majority. It stays a follower and catches up via AppendEntries.
1if !n.isLogUpToDate(req.LastLogTerm, req.LastLogIndex) {
2 n.logger.Info("vote denied: stale log",
3 zap.String("candidate", req.CandidateID),
4 zap.Uint64("candidate_last_index", req.LastLogIndex),
5 zap.Uint64("candidate_last_term", req.LastLogTerm),
6 )
7 return VoteResponse{Term: n.currentTerm, VoteGranted: false}
8}1if !n.isLogUpToDate(req.LastLogTerm, req.LastLogIndex) {
2 n.logger.Info("vote denied: stale log",
3 zap.String("candidate", req.CandidateID),
4 zap.Uint64("candidate_last_index", req.LastLogIndex),
5 zap.Uint64("candidate_last_term", req.LastLogTerm),
6 )
7 return VoteResponse{Term: n.currentTerm, VoteGranted: false}
8}Removing this check is a data-loss bug. The only way to feel why it matters is to build the scenario and watch the stale node try and fail to become leader.
Failure 3: Torn Writes in the WAL
When Raftly writes an entry to the WAL, the sequence is:
wal.SaveEntry(entry) // buffered write
wal.Sync() // fsync — blocks until the kernel confirms durabilitywal.SaveEntry(entry) // buffered write
wal.Sync() // fsync — blocks until the kernel confirms durabilityIn the real world, a lot can go wrong. The process can be killed mid-write. The OS can crash. The cloud VM can be live-migrated. What ends up on disk could be a partial record: a classic torn write.
If a torn write is silently accepted as valid, we can resurrect a half-written entry that was never actually committed, and our log diverges from the rest of the cluster.
The defense against this situation is that every WAL record should have a CRC32 suffix. On startup, ReadAll() walks the file, verifies each checksum, and stops at the first mismatch. Every record before the torn write is restored. Every byte after is discarded. The node rejoins the cluster and catches up via normal replication.
// ReadAll()
if expected != actual {
break // torn write detected — recovery boundary
}// ReadAll()
if expected != actual {
break // torn write detected — recovery boundary
}The scenario reproduces this by crashing the node, appending random garbage to the WAL file, restarting, and checking that recovery detects the corruption at the right boundary. Seeing the node come back online with its log correctly truncated to the last intact entry is satisfying in a way that reading about CRCs is not.
One subtlety worth calling out: CRC32 is not cryptographically strong. It won't protect us against a motivated attacker substituting a crafted record. But torn writes are not adversarial — they are accidents of buffering. CRC32 reliably detects accidental corruption at vanishingly small cost per write.
Failure 4: Leader Crash After WAL Write, Before Replication
The leader writes an entry to WAL, calls Sync(), appends it to the in-memory log, then crashes before sending AppendEntries.
The entry is in the leader's WAL. When it recovers and wins the next election, it will have that entry and try to replicate it. It will be replicated and committed normally.
What if the leader doesn't recover, and a different node wins? That node's log might not have the entry. The entry was never replicated to a majority, so it was never committed. The new leader can overwrite it. The client's Propose() call returned an error (the leader crashed before committing). The entry is gone but that's correct. It was never committed.
Failure 5: Disruptive Follower (Pre-Vote Required)
Node C is partitioned. Node A is leader. Node C's election timer fires repeatedly. Its term climbs to 50, 100, 200.
When node C reconnects without pre-vote, it sends RequestVote with Term: 200. Node A receives this, sees the higher term, and must step down immediately. The cluster spends time on an unnecessary election. With a long enough partition, this causes repeated availability hiccups every time a partitioned node reconnects.
With pre-vote enabled, every one of node C's pre-vote requests during the partition is rejected by nodes A and B because they have an active leader. Node C's term never advances. When it reconnects, it sends a RequestVote at its last pre-partition term where it has no advantage. It simply syncs up as a follower.
We can observe this directly via Prometheus: without pre-vote, raftly_elections_total climbs during the partition and raftly_leader_changes_total spikes on reconnect. With pre-vote enabled, neither metric moves during the partition.
Performance Surprises: Opportunistic Group Commit
I wrote Raftly's benchmark suite expecting to confirm an intuition: throughput under concurrent load should stay flat because every Propose() has to serialize on the WAL's fsync, and fsync is the bottleneck.
This is what I actually measured, on a MacBook Pro M3 with an in-memory transport:
| Concurrency | ns/op | vs c1 |
|---|---|---|
| c1 | 6.5ms | — |
| c4 | 4.1ms | 37% ↓ |
| c16 | 3.8ms | 41% ↓ |
| c64 | 3.5ms | 46% ↓ |
Throughput did not stay flat. It got better under concurrency, by almost half. My prediction was wrong.
The explanation is opportunistic group commit. Here's what actually happens under the lock:
- 64 goroutines call
Propose()at roughly the same time. - They queue on
n.mu. - The first one enters the critical section, writes its entry to the WAL, and releases the lock.
- Before the WAL is flushed, the second goroutine enters and writes its entry. And so on.
- When
maybeSendHeartbeats()runs, it sends a singleAppendEntriesto each follower containing all the queued entries. - Each follower does a single
fsyncfor the entire batch. - When the quorum acks, all 64 proposers unblock at once.
One RPC per follower. One fsync per node. 64 proposals committed. This is exactly the economic structure of Kafka's producer batching, but it emerges for free from the combination of mutex contention and the replication loop. We don't have to design for it. We just need to not accidentally design around it.
After this discovery, I added a latency-percentiles benchmark:
p50 = 6.7ms
p95 = 9.9ms
p99 = 12.4msp50 = 6.7ms
p95 = 9.9ms
p99 = 12.4msA p99/p50 ratio of 1.85 is healthy — production consensus systems start worrying when that ratio exceeds 10×. The tail here is bounded by occasional elections and ordinary disk flush variance.
The Heartbeat Bug That Taught Me About Latency
Before the concurrent benchmark, I ran a single-threaded benchmark on a single-node cluster and measured proposal latency of ~50ms. For a single-node, in-memory cluster with no network and no quorum to wait for, 50ms is completely wrong. The only real work is a WAL write and an in-memory commit. That should take microseconds.
I spent an hour tracing through the code before I found it. Commit advancement depended on maybeSendHeartbeats() being called, and that function was only called every 50ms by the heartbeat tick. Single-node proposals were literally waiting for the next heartbeat tick before committing. The fix was one line:
if err = n.log.Append([]LogEntry{entry}); err != nil {
return 0, 0, fmt.Errorf("log append: %w", err)
}
go n.maybeSendHeartbeats() // trigger commit advancement immediatelyif err = n.log.Append([]LogEntry{entry}); err != nil {
return 0, 0, fmt.Errorf("log append: %w", err)
}
go n.maybeSendHeartbeats() // trigger commit advancement immediatelySingle-node latency dropped from ~50ms to ~2.3ms. A 22× improvement from moving one function call. This is not a clever optimization at all but a bug that I introduced by not thinking carefully enough about the control flow on the happy path. The reason I found it is that I had a benchmark, ran it, and trusted the number.
Measurements are not optional for systems work. Reasoning about performance without measuring is how you ship a system with a 22× latency regression and never notice.
The Meta-Lesson
If this post has a thesis beyond "here's a Raft implementation," it is this: there is a specific kind of understanding that comes from building systems with the goal of breaking them, and that understanding is not accessible through any other means.
Reading the Raft paper teaches you the algorithm. Implementing it on the happy path teaches you the data structures. But the invariants i.e., the things Raft is actually protecting — only become visceral when you watch them being violated and restored.
A few specific observations that generalized beyond Raftly:
Durability is measurable, not theoretical. The difference between write() and fsync() and the CRC32 guard is not an academic distinction. Every durable system has to defend against torn writes, and the defense is physical: a checksum, a recovery procedure, a test that reproduces the failure. If the system does not have all three, it does not have durability, only hope.
Availability is a distribution, not a number. The election time in Raftly is not "155ms". It is a distribution shaped by randomized timeouts, network round-trip, disk flush, and occasional vote splits. Any availability claim without a percentile is just marketing, not engineering.
Concurrency can be an optimization you didn't design. The opportunistic group commit was a gift. I did not build it. It emerged from the mutex and the replication loop. Most of the clever optimizations in production distributed systems are emergent behaviors that you can either nurture or accidentally destroy. The designer's job is to be aware of them and not get in their way.
Benchmarks lie less than intuition. My prediction about concurrent throughput was exactly backwards, and I was confident enough to write the wrong comment into the benchmark source code before running it. The benchmark corrected me in thirty seconds. If you are not regularly surprised by your own measurements, you are not measuring often enough.
What's Missing
Raftly is not a production system. I want to be clear about what it deliberately doesn't have:
- No snapshot/compaction. The log grows forever. A production system needs to periodically snapshot the state machine and truncate the log. I understood the mechanism from the paper and decided the learning value of implementing it was lower than the learning value of building more failure scenarios.
- No joint consensus for membership changes. Adding or removing nodes from a running cluster safely is a non-trivial protocol in its own right.
- No lease reads. Leader reads in Raftly go through the replication protocol. Production systems like etcd and TiKV use lease-based reads for lower latency, which requires physical clock assumptions.
- No Byzantine fault tolerance. Raft assumes non-Byzantine failures. BFT is a different problem with different algorithms (PBFT, HotStuff).
If I were productionizing Raftly, all four of these would be on the roadmap. As a laboratory for understanding consensus failure modes, none of them were required. A principled engineer decides what not to build and writes that decision down.
Conclusion
The TL;DR, if you want one:
- Raft is an algorithm that is easy to read and hard to understand. The difference is in the failure modes it defends against.
- The best way to understand a distributed systems algorithm is to build a laboratory version and break it on purpose. Reading is necessary but not sufficient.
- The defenses that matter: quorum, pre-vote, election restriction, CRC32 guards are each one to ten lines of code. They are cheap to implement and catastrophic to omit.
- Measurements are how we find out our intuition was wrong. Build the benchmark harness. Trust the numbers.
- Production durability and availability are physical properties, not paper properties. You have them only to the extent you can reproduce and survive the failure modes that threaten them.
I learned more about distributed systems from deliberately breaking Raftly than I did from any course, book, or paper that came before it. I strongly suspect this is the general shape of how hard technical understanding actually gets built: by the engineer who, instead of reading about the 2011 AWS incident, builds a small machine that reproduces its essential shape and sits with it until the reason the defenses exist becomes obvious.
The code is on GitHub if you want to run the scenarios yourself. They each take under a minute. I recommend the split-brain one first.
Namaste! 🙏
The Main Thread
I write a weekly deep dive like this one on distributed systems and AI engineering. One issue every week, straight to your inbox.
References
Production Incident Reports
AWS 2011 EBS incident — Summary of the Amazon EC2 and Amazon RDS Service Disruption in the US East Region, April 2011. The canonical post-mortem for split-brain under a network configuration change.
Foundational Papers
Raft — Ongaro, D. & Ousterhout, J. (2014). In Search of an Understandable Consensus Algorithm (Extended Version). The paper. Read it at least twice. Implement it at least once.
FLP Impossibility — Fischer, M. J., Lynch, N. A., & Paterson, M. S. (1985). Impossibility of Distributed Consensus with One Faulty Process. Journal of the ACM.
Paxos Made Simple — Lamport, L. (2001). Paxos Made Simple. The precursor that Raft was written as a reaction to.
Production Raft Implementations
etcd/raft — github.com/etcd-io/etcd/tree/main/raft. The gold standard Go implementation. Backs etcd, CockroachDB, TiKV.
hashicorp/raft — github.com/hashicorp/raft. Used in Consul, Nomad, Vault.
Books
Designing Data-Intensive Applications — Kleppmann, M. Chapter 9 on consistency and consensus is the best survey of the space I have read.
Database Internals — Petrov, A. Chapter 14 on consensus protocols complements Kleppmann with more implementation-oriented depth.
Courses
MIT 6.824: Distributed Systems — pdos.csail.mit.edu/6.824. Robert Morris's labs walk you through implementing Raft incrementally. Do them.
Raftly
Source code — github.com/ani03sha/raftly. The implementation, the scenarios, the benchmarks, and the README that tells this story as a reference document rather than a narrative.
Written by Anirudh Sharma
Published on April 13, 2026